The Open Low-Code Platform
Quickly build powerful multi-user applications to meet software requirements - goodbye spreadsheets, shared mailboxes and other 'solutions'.
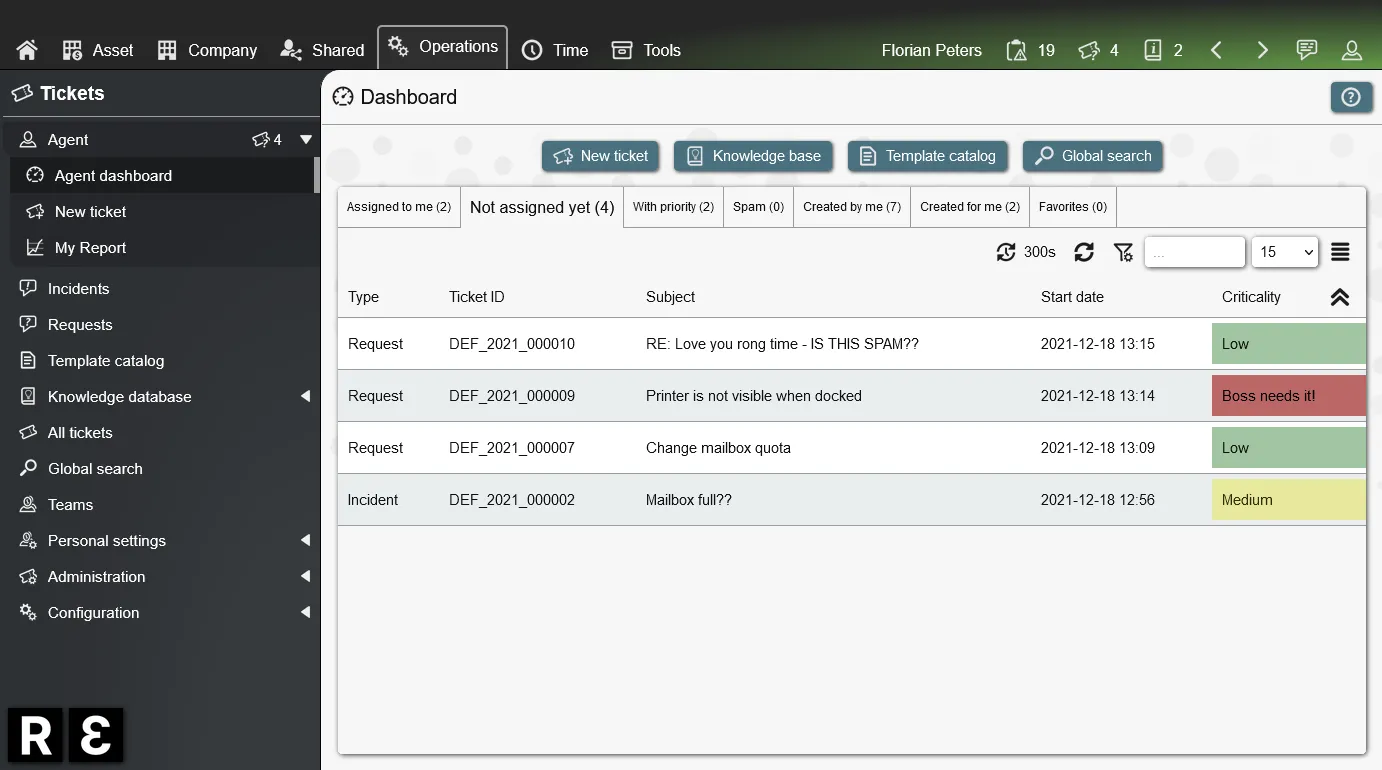
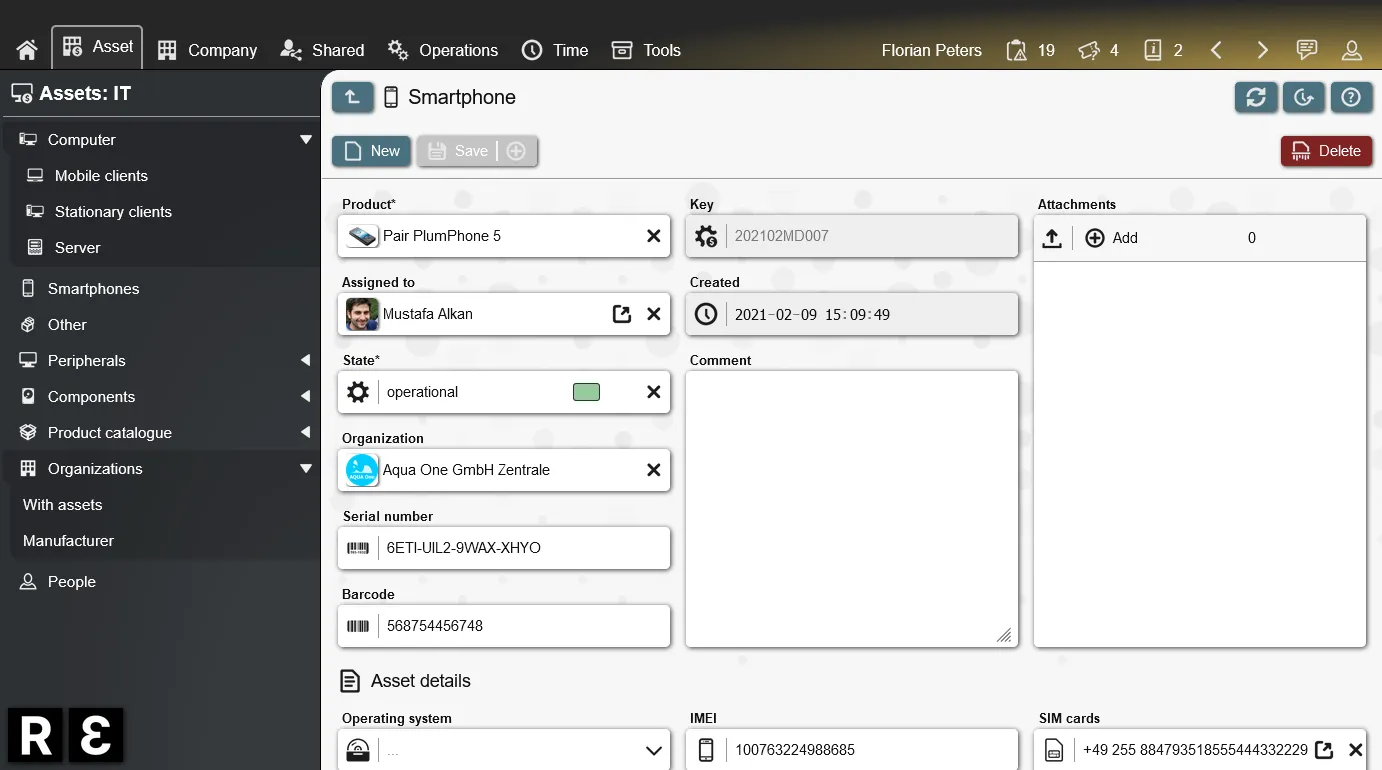
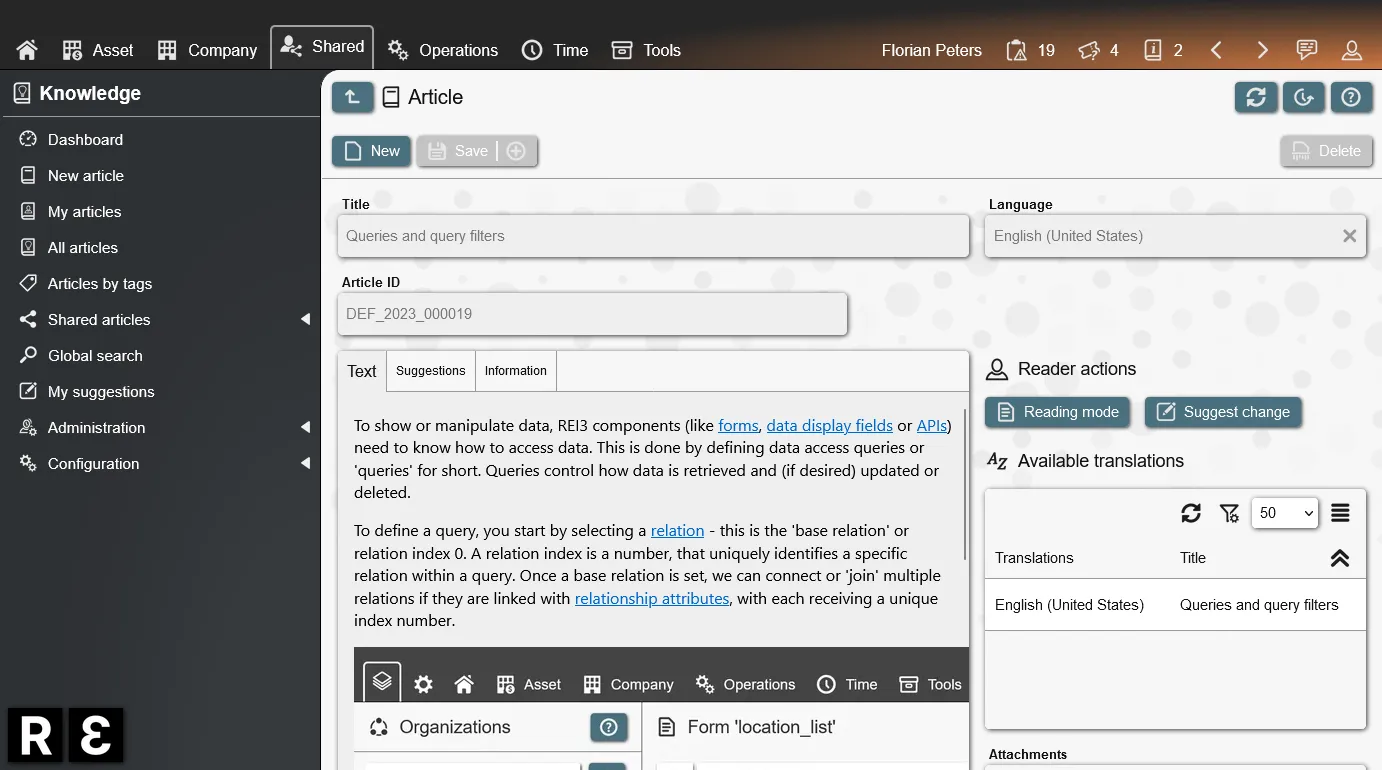
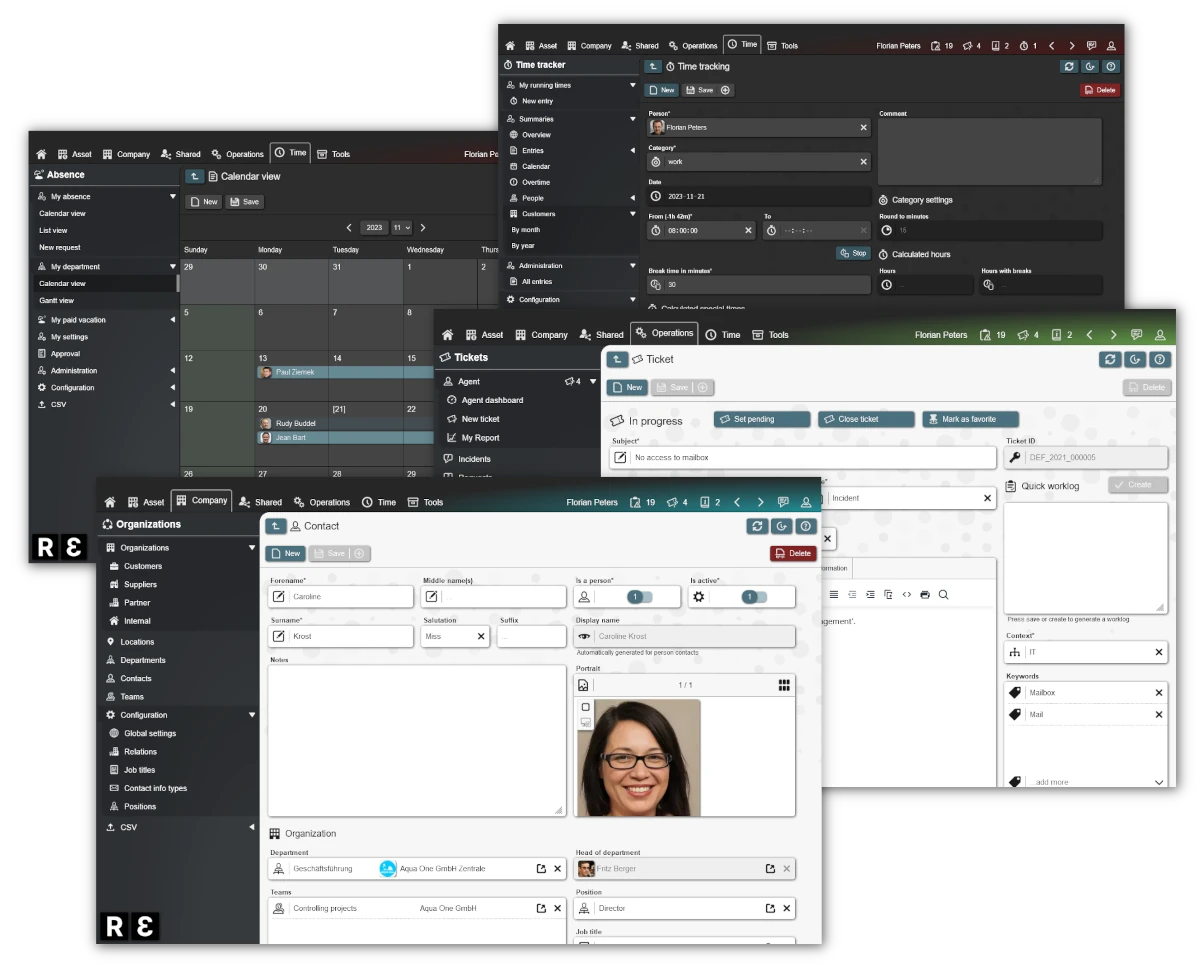
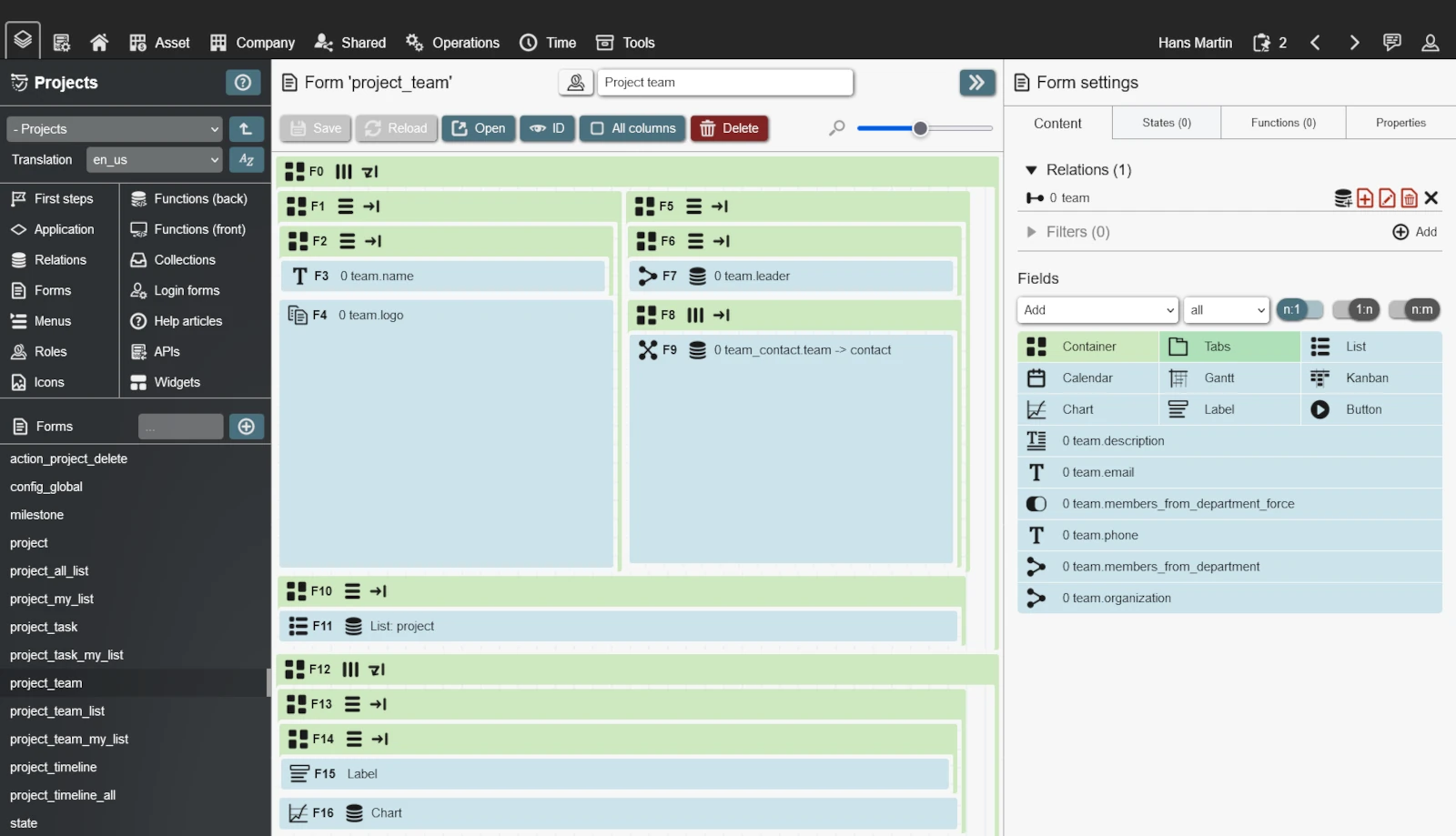
Create data stores, build forms, setup workflows, control access, call APIs, schedule notifications and much more. Everything integrated into the open-source low-code platform REI3. Free to use for everyone.
Stay independent with full authorship over your applications and where your data is stored - on-premise, in the cloud - self-hosted or however you want.
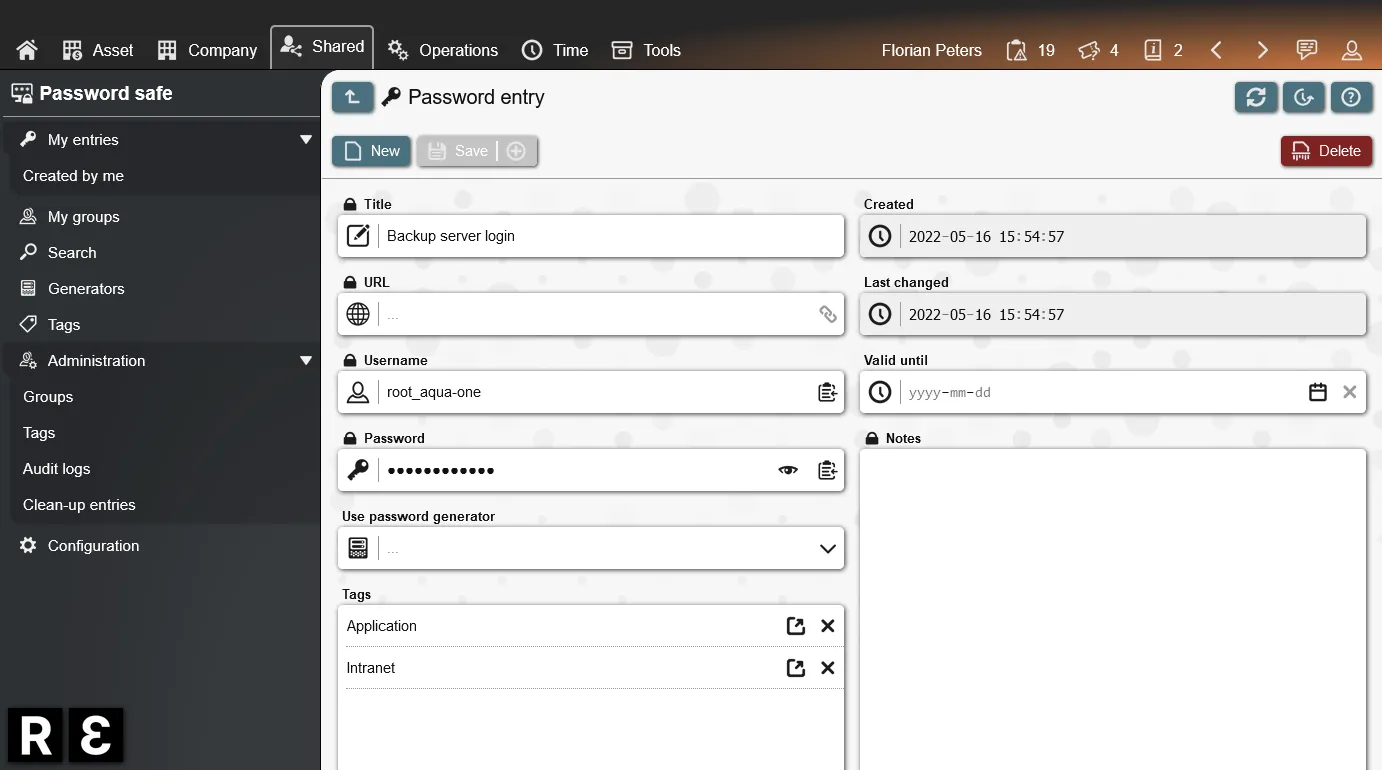
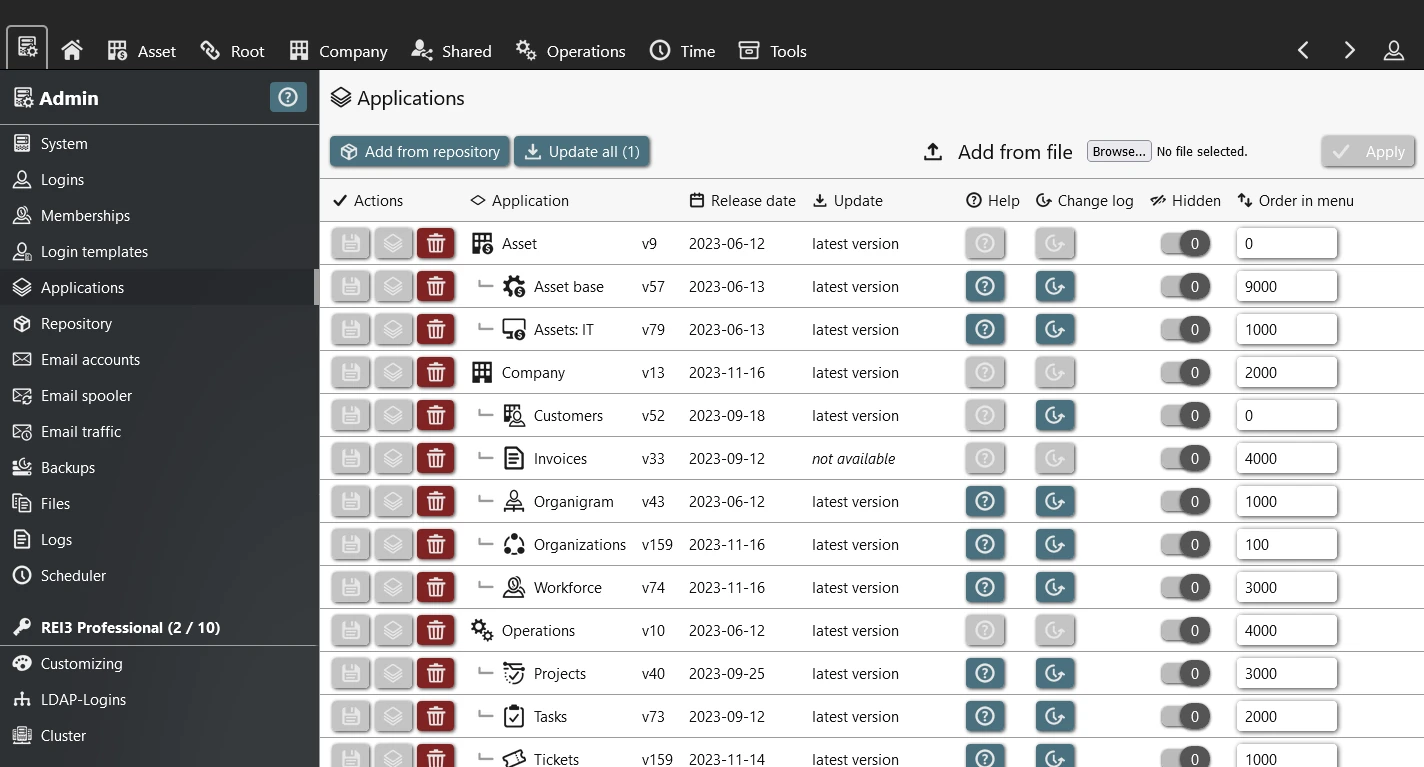
Address common requirements with existing REI3 applications. From time tracking, to request handling, to secure password sharing. Most are freely available.
Run your own REI3 system for private or commercial use, 100% free of charge - enterprise features & services are available if needed.