- Introduction
- The Builder
- Getting started
- Data storage
- Roles and access management
- Presentation and user interfaces
- Functions
- Variables
- APIs
- Search bars
- Collections
- Widgets
- Client-Events
- End-to-end encryption
- Building on applications
- Application transfers
- Optimizing for mobile devices
- Working with emails
- Date and time management
- User sync
- CSV import and export
- Troubleshooting
Updated 2025-07-07
Introduction
This is the documentation for building REI3 applications. REI3 is a free to use, open-source business application platform, which can run on-premise or from the cloud, on Windows and Linux. To learn how to setup and administrate REI3, please refer to the admin documentation.
REI3´s primary purpose is to fulfill business software requirements. Simple applications, like a system that manages company event attendance, can be built within an hour. More complex requirements, like tracking and managing employee absence or executing mail campaigns, can also be fulfilled. Organizations using REI3 can save time and money by reducing their dependency on costly software solutions for simple tasks, while cheaply addressing complex, niche requirements that no fitting solution is available for.
Most people with IT administration skills can use REI3 to address their software needs; it is however very useful to know relational databases to make use of all features. REI3 provides access to low-level entities, such as database indexes, triggers, sub queries, functions and so on. With some background knowledge, complex relationships, business logic, access control as well as performance tuning can be implemented to build powerful, fast and scalable applications.
The Builder
REI3 applications are created and updated with a graphical utility, called 'Builder'. The Builder is included in all releases of REI3 and can be enabled by an admin user.
Finished applications can be exported and then imported into other REI3 instances, to deploy changes to production systems or to share applications with others. There is a dedicated REI3 application available (REI3 Repository) to host and distribute other REI3 applications publicly or inside internal networks.
Be aware: Changing an application with the Builder can result in changes to the underlying data structure, potentially deleting data in the instance but also in other instances when transferring an application. Precautions must be taken accordingly:
- NEVER use the Builder in productive instances. To build, use the portable version of REI3 or run a separate REI3 instance. For critical instances, it is smart to run a copy of a productive system to confirm application changes before deploying to the final, productive instance.
- DO NOT make changes to applications from other authors - these are deleted when the application is updated. You can expand existing applications safely by adding custom data & user interfaces on top of them inside your own applications. Please refer to Building on applications to learn more.
- ALWAYS consider carefully when deciding to delete data structures (relations/attributes). This will affect target instances and, if other applications build on yours, affect other applications as well. Renaming data structures is safe however.
To enable the Builder, you need to log into a running REI3 instance with an admin user. After enabling the maintenance mode, which will kick all non-admin users from the system, the Builder can be switched on. Once activated, the Builder can be accessed from its icon on the top-left corner of the main menu.
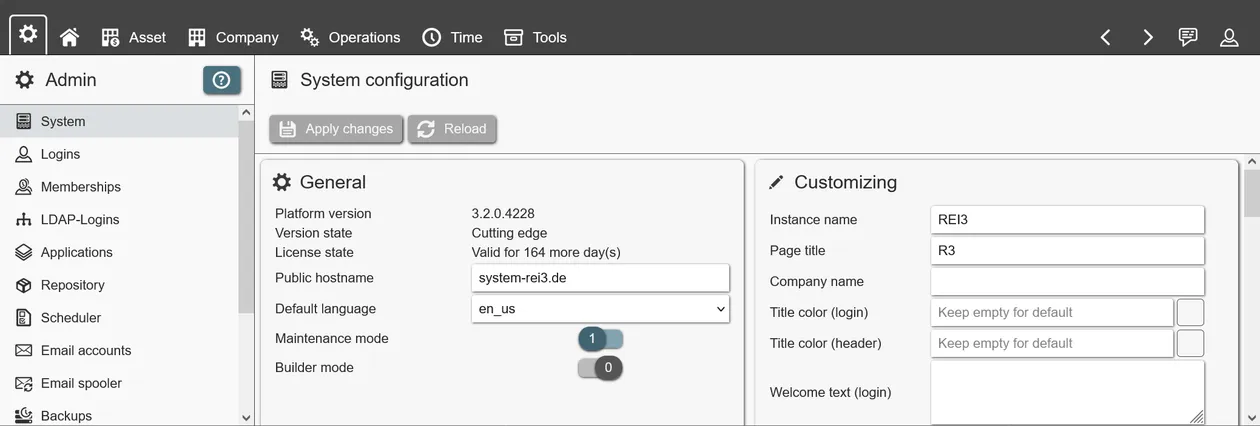
Getting started
To start, you can either directly create your own application, or install existing ones from the public repository.
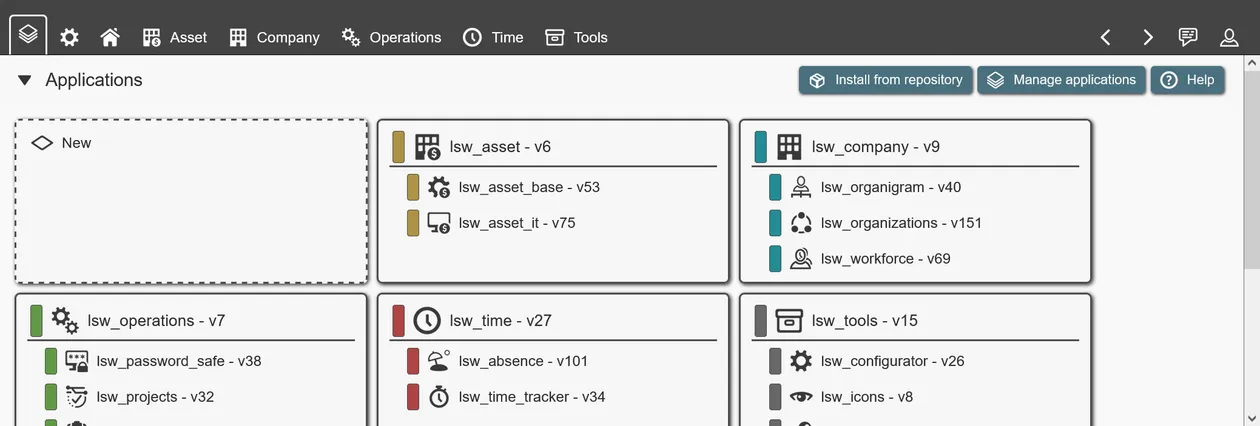
Installing applications as reference
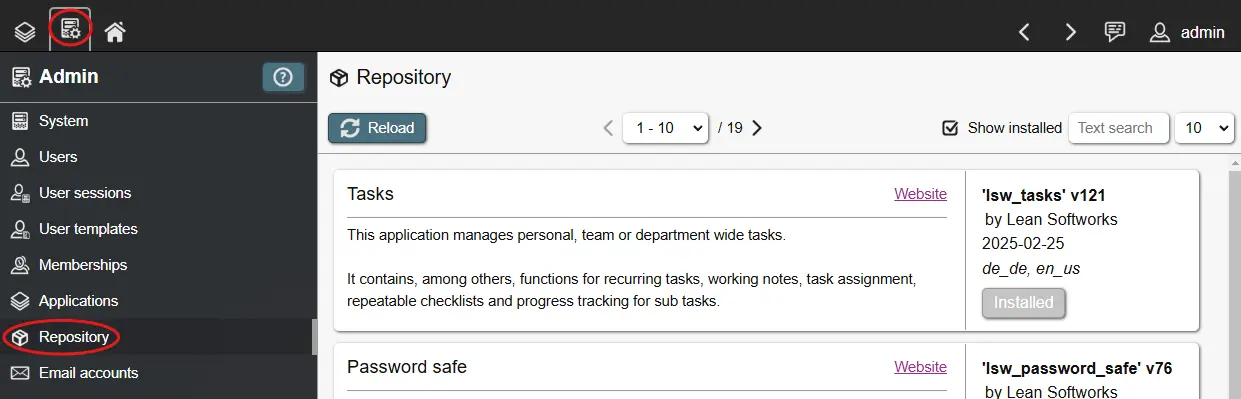
To play around and see working examples, you can install applications from the public repository inside the admin interface. In a non-productive instance you can install, change, delete and re-install applications at any time. Installing finished applications can help with understanding how these are built and how specific options are used.
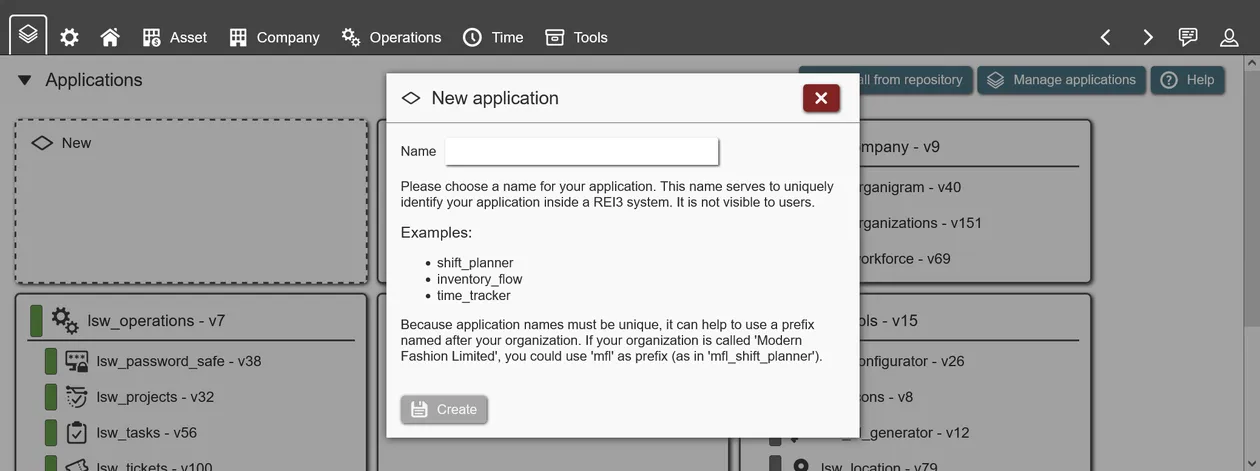
Creating your own applications
Creating a new application is straightforward. After opening the Builder, a list of installed applications is presented to you. After clicking on 'new', enter a unique name for your application and save - a new application is generated. You can then open the application to work on it.
There a few options when creating or updating the application itself:
- Name: A unique name, representing your application. Only important for transferring your application to other instances - users see a translated application title instead (see below).
- Builds on (optional): When other applications are installed in the same REI3 instance, they can be selected here. Each selected application can then be referenced inside the Builder to reuse data, user interfaces, icons and so on. More details in Building on applications.
- Assigned to (optional): Application which serves as a parent to your application. Must be selected in 'builds on' first. This option effectively creates a hierarchy in the start and header menus. Currently the hierarchy is limited to 2 levels (1 parent, multiple children).
- Icon (optional): An icon representing the application. Must be added to the application first.
- Color (optional): Freely selectable color. Is shown on the start page and on the header when the application is active. Can be overwritten in instances with customizing. Should be a color with low-brightness to contrast bright header fonts.
- Default position: Order in which the application should appear in menus (smaller first). Is only applied once during installation of the application. Order can be overwritten in instances by admins. When 'assigned to' a parent application, positions affect the order underneath the parent application.
- Start form (optional): Depending on assigned roles, a different form can be shown when opening the application. Multiple rules for matching role membership with start form can be set; if no rule matches, the default start form is shown. A valid start form is required for the application to show up in the user´s menu.
- Languages (1 is required): Languages, the application is available in. A language is defined by its 5-letter language code (en_us, de_de, ch_cn, and so on). Be aware: You must provide translations for all languages that you define here - not doing this results in error strings being shown to users. Besides the application title, other entities (menus, forms, help pages, ...) require translations when creating them. You can also define a fallback language, which is used if a user selects a language that your application does not offer. To start, you should keep to a single translation and expand when needed.
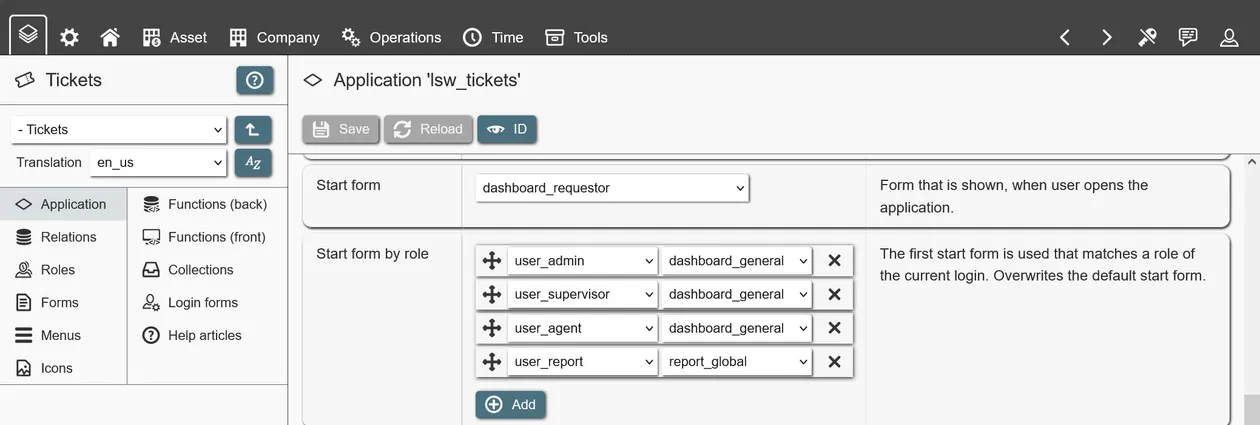
Some options depend on other entities being created first (other applications to build on, forms to select as start form, icons to show). When creating an application these can be skipped and updated later.
In addition, a couple of non-editable fields are shown. These are set when an application is exported. Please refer to Application transfers for more details.
- Release date: Current date when exported.
- Application version: Incremented by 1 when exported.
- Platform version: Version of the REI3 instance when exported.
Data storage
Applications that work with data usually need some sort of long-term data storage. REI3 is built on the well-established, relational database management system postgreSQL.
To store data in a relational database system, 'relations' are created in the form of database tables. Relations contain records for named entities (for example students and classes of a school) and can be used to implement relationships between them (which students attend which classes). Relations, their attributes and, by extension, relationships work the same way in REI3 as they would when building an application with any common relational database system.
Relations and attributes are referenced in forms to display, create or update data in lists, fields, calendars and so on. They are also accessible in backend functions for complex data manipulation, calculations or other data related actions.
Relations
Relations are used to store data in the form of records. Records can be anything, from company contacts, students, vehicles, locations - to invoices and workflows. By creating multiple relations, you can store any data your application needs.
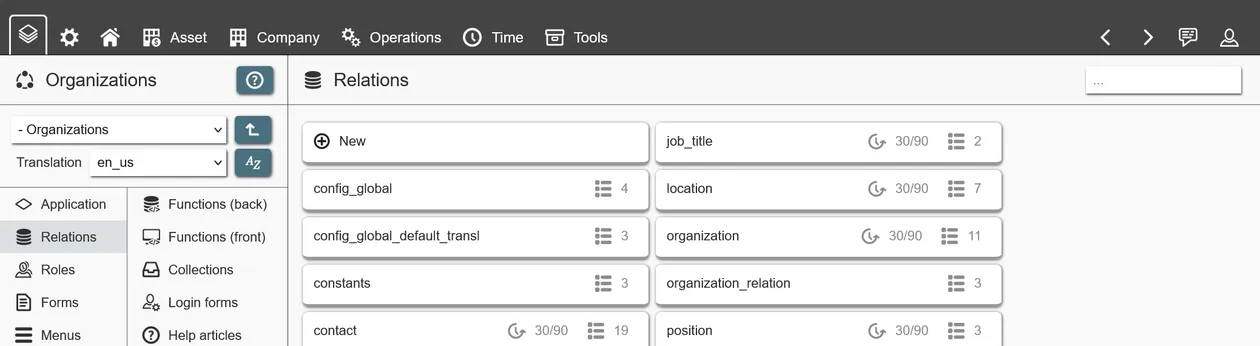
The following options are available for relations:
- Name: The internal name of the relation; it should reflect the contents of the relation and must be unique within the application.
- E2E encryption: This enables end-to-end encryption or E2EE for this relation. E2EE has benefits and drawbacks and should only be enabled were needed. This settings cannot be changed later for this relation. Please read the corresponding chapter before enabling it.
- Policies: Are used to control, which records of a relation are accessible to which user based on filtering done on the backend - more details.
- Change log: Data retention settings for the relation.
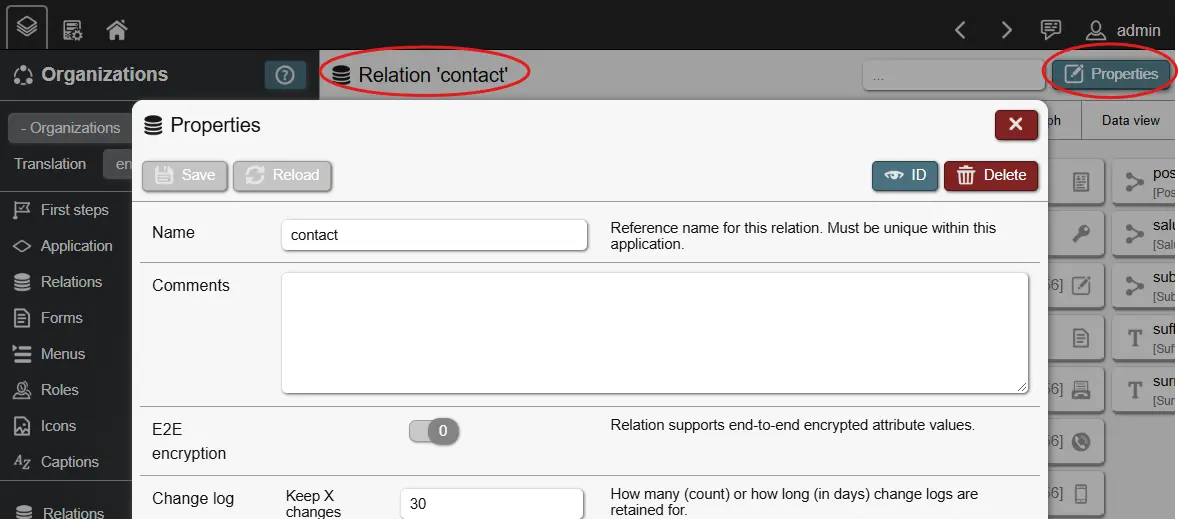
Relations are central to managing data in REI3. They contain all records, their values (following their attributes), indexes (mostly for performance tuning), presets (predefined records) and triggers (automatically executed backend functions).
Attributes
Once a relation has been created, you can create attributes for it. An attribute is a data field, which is available to every record in a relation. A relation called 'contacts' might have attributes such as 'email', 'phone_number' and 'works_at_company'.
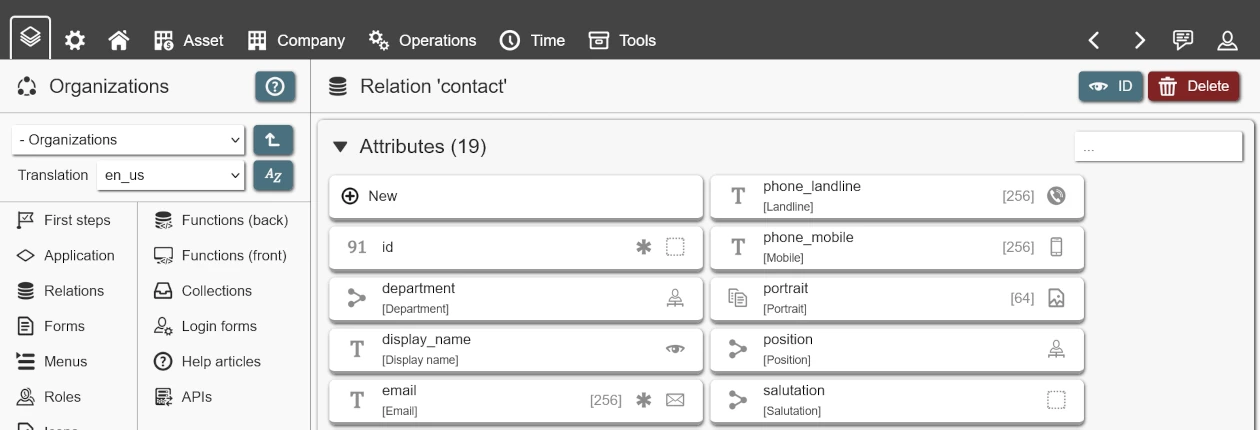
The following options are available for attributes:
- Icon: Default icon for this attribute. Used by input fields on data forms if no other icon is defined.
- Name: Attribute name, needs to be unique within the relation. Used as reference throughout the Builder.
- Title: A translated title - displayed in input fields and columns if not overwritten.
- Value type: What value an attribute can hold. Frontend elements, like input fields or list columns will handle values according to this selection.
- Text: A string of characters, which can represent anything from names and phone numbers, to email addresses and postal codes.
- Text, multiple lines: The same as text, but frontend elements will offer multiline inputs for larger content, like notes or descriptions.
- Text, with formatting: Similar to text, but frontend elements will offer richtext editor options for formatted text, tables, images and more.
- Number, whole: A number without decimal component.
- Number, decimal: A number with decimal component. Often used for currencies or measurements. Useful for exact storage but slower for complex calculations compared to 'Number, floating' (s. below).
- Number, floating: A number with a floating decimal. Less exact than numeric but faster for complex calculations. Often used for approximations.
- Color: A RGB color value. Frontend elements will present a color picker in inputs and color values in views. Can be used to color calendar entries and list columns.
- Files: References to uploaded files. Frontend elements will present file management interfaces in inputs and either image previews or download links in lists or other views, depending on field options.
- Yes/no: A simple boolean (TRUE/FALSE) value. Presents as a toggle in inputs.
- Barcode/QR code: A bar- or QR code, stored in JSON format, including the code value, format (UPC, EAN, QR, ...) and base64 image. In forms, the corresponding inputs can be used to scan codes via camera. Users can also manually enter codes and choose the desired format to generate previews. In views, like list fields, either the code value or code image can be shown.
- Drawing: A simple drawing, stored in JSON format, including the strokes (length, width, color) and base64 image. Can be used to offer note or signature pad inputs.
- Date + time: A date value with time component. Often used for events or timestamps (when did something happen). Frontend elements will present date/time pickers in inputs and date/time values, formatted according to user settings, in views like lists.
- Date: Like 'date + time' but without the time component. Often used for simple dates, like 'date of purchase' or 'birthday'.
- Time: Just a time without any date context. Stores hours + minutes + seconds. Can be used for things like time trackers.
- Relationship (n:1): Stores a reference value to another record, usually on another relation. Used to build relationships like 'student attends class' or 'employee belongs to company'.
- Relationship (1:1): Like 'relationship n:1', but the specific relationship must only exist once inside a relation. This is often used for relationships like 'owner of a car' or 'teacher of a class' - in these cases only a single person can be the owner of a car or teacher of a class.
- Universally unique identifier (UUID): A 128bit label used to identify an entity. UUID values are statistically extremely unlikely to ever exist twice, even if they are created in different, disconnected systems. Useful to create unique keys for data exchange between systems.
- Text search dictionary: A name of a language. Used for text indexes to know which language another text attribute on the same relation is in. The number of available languages depends on which languages the database system supports.
- Max. size in KB: Only for value type 'Files'. Limits max. upload size for each file. 0 equals not limited.
- Max. characters: Only for value type 'Text'. Limits the amount of characters allowed. 0 equals not limited.
- Number of digits: Only for value type 'Number, decimal'. Defines how many digits should be stored before and after the decimal point.
- If both values are set to '0', the numeric value is unconstrained (max. 131072 digits before & 16383 after the decimal point). With an unconstrained decimal value, the system will store and display values as entered, though in many situations setting constraints is more sensible.
- For monetary values, 12 digits before and 2 after are good practice, allowing for numbers up to '999.999.999.999,99' with a precision up to 1 cent.
- If number of digits is defined, inputs and views (like list fields) can fill up empty decimal spaces so numbers become aligned and easier to compare.
- On fields, settings like 'Alignment' and 'Monospace' can further improve numeric value input.
- When updating the number of digits of an attribute, the system will round values if the new definition for decimal places is smaller. This is permanent and is not reversable without backups.
- Must have value: Attribute values must not be empty (NULL). If enabled, records without this attribute value cannot be saved.
- E2E encrypted: Enables end-to-end encryption for this attribute. Only available for new attributes and for relations with E2E encryption enabled.
- Default: If no attribute value is given, this default value is applied.
- ON UPDATE/DELETE: Only for value type 'Relationship'. These define how records, connected via a relationship, react when their partner is updated or deleted (refer to relationships for more details).
By default, an attribute with the name 'id' exists for each relation and cannot be deleted. This is its primary key. A primary key serves to reference each specific record by a unique value - in this case, its an automatically created number (auto-incremented integer).
Other attributes can also be used as keys, for example when using unique names or reference numbers.
Relationships
Two relations can be in a relationship by creating a 'relationship attribute' on either one of them, which refers to the other. You can choose a 1:1 (one-to-one) or N:1 (many-to-one) relationship. Some examples:
- 1:1 - one-to-one
- Relation 1: asset (contains asset details like a unique asset number)
- Relation 2: asset_purchase (contains purchasing details for one asset like its invoice number and paid price)
- -> The relationship attribute can be on either relation 1 or 2. Only one asset can have the specific asset purchasing details (1 'asset' record is connected to 1 'asset_purchase' record - 1:1).
- N:1 - many-to-one
- Relation 1: asset (contains asset details like a unique asset number)
- Relation 2: product (contains product details, like model name, manufacturer)
- -> The relationship attribute (as in N:1 'asset_product') must be on relation 1. Multiple assets can be the same product (many asset records are connected to 1 product record - N:1).
A N:M (many-to-many) relationship can be created between two relations by creating a third relation with two N:1 attributes. This third relation can then hold other attributes as well, adding details to the N:M relationship. Example:
- Relation 1: student (contains student details, like name, date of birth, ...)
- Relation 2: class (contains class details, like a description, assigned teacher, ...)
- Relation 3: student_class (N:1 attribute to 'student', N:1 attribute to 'class', integer attribute 'started_in_year' to describe first year of student attendance)
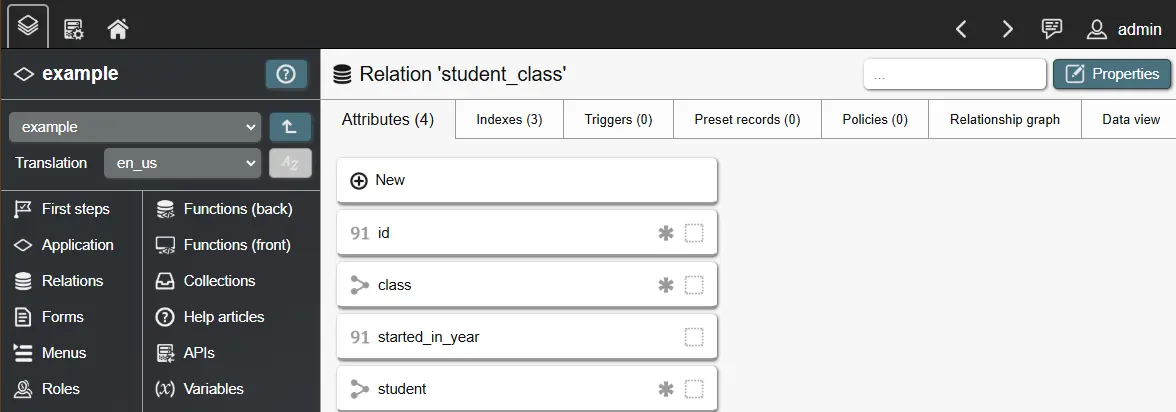
Relationship attributes use foreign keys to enforce the existence of referenced records. When a record that serves as relationship target is deleted, the foreign key becomes invalid. This also occurs, although more rarely, when the referenced key of such a record is changed. To deal with these cases, you can specify a desired behavior for 'ON DELETE' (referenced record is deleted) and 'ON UPDATE' (key of referenced record is changed):
- NO ACTION: Block the deletion of the original record.
- RESTRICT: Similar to NO ACTION, but does not allow deferring in a running transaction. This option is only relevant for experts.
- CASCADE: Delete the record which is referencing the invalid relationship target. Often used in parent-to-child relationships - when parent is deleted, delete all children automatically.
- SET NULL: Replace the invalid value with NULL. Only works if the relationship attribute is nullable.
- SET DEFAULT: Replace the invalid value with defined default value. Only works if a default value is set.
Presets
Presets are predefined records that are shipped with your application. A preset consists of a name as well as attribute values. The preset name only serves as reference inside the Builder - it is not visible to any end user. When your application is transferred to a target instance, one record for each preset is created in the corresponding relation. All defined attribute values are applied to this record.
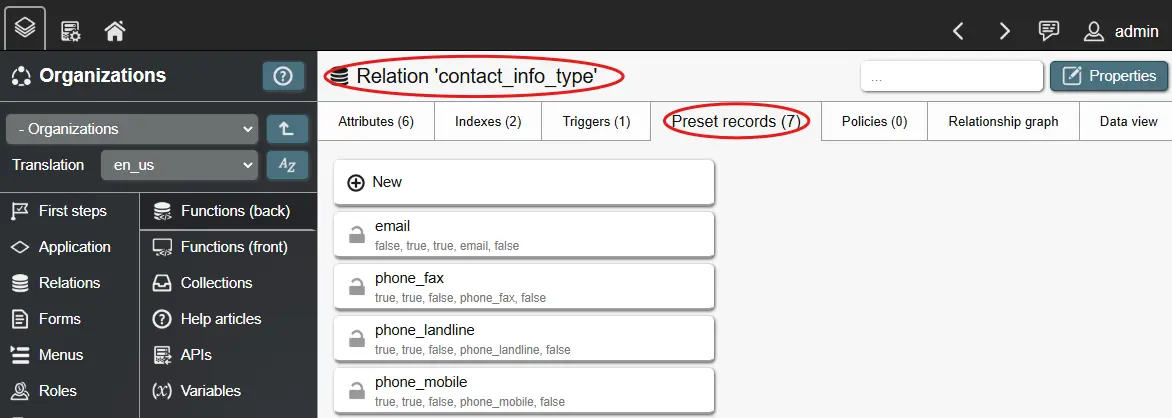
When you define a preset, you can choose to protect it and/or its attribute values. Protecting the preset itself, blocks deletion of its associated record, while protecting attribute values blocks updating these values. The protection settings can be mixed to serve different purposes:
- Protected record & protected values. For records that must stay a certain way for your application to work properly; this can be useful for workflow states.
- Protected record & unprotected values. Useful for central configuration records with customizable options.
- Unprotected record & protected values. Useful for cases in which a record is optional, but its values need to stay a certain way to be sensible.
- Unprotected record & unprotected values. Useful for sample data - can be overwritten, changed or deleted at will.
Important! When a record or its values are unprotected, they can be deleted/changed in the target instance. When updating your application in the instance, already deleted/changed preset records are not recreated or updated. REI3 follows this definition: An unprotected preset/value is optional and if a user in the target instance decides to delete/change it, it will stay that way.
Protected presets/preset values on the other hand are always updated. Since deletion/change is blocked, updates only occur if presets have changed themselves. When switching an unprotected preset/preset value to 'protected', deleted/changed presets/preset values are recreated/updated.
Preset values must be defined as their original value state. To see this state, you can open the data view on any relation; this will show the original attribute values. Some examples:
- Boolean values must be defined as TRUE/FALSE
- Date/time values must be defined in unix time (seconds since 1970-01-01 in UTC)
- File values (e. g. uploaded files) can currently not be added as presets.
Lastly, deleting presets will delete associated records as well. Independently of the protection setting, records of deleted presets will be deleted in the target instance during transfer.
Indexing
Indexes are defined on relations. They serve to improve the speed, in which data can be looked up from the database, which leads to a better user experience. They are optional for smaller relations but become very relevant, when records inside a relation keep growing in number.
Standard principles of indexing, which is part of any relational database management system, can directly be applied. Here are some basics - for more details, please lookup other resources on database indexing:
- Indexes help the database system find specific records without having to scan all records in a relation.
- Indexes can have a big impact on performance - especially on larger relations. A good index can speed up data retrieval a thousand-fold.
- As indexes serve to find records by certain criteria, attributes that are used in filters benefit from indexing a lot.
- Having indexes for specific attributes is important for good database performance; creating indexes for all attributes is a bad idea however. The more indexes exist, the slower changes to records become as indexes must be updated as well. In addition, each index has storage overhead, adding to the database size.
- Unique indexes can be used to enforce unique values in all kinds of attributes (unique names/numbers/dates/...). This is one use-case for indexing besides performance.
- Indexes can be used to enforce unique, composite keys by using multiple attributes to form a unique index.
Indexes become very important when executing application wide searches, such as when using search bars.
Text indexing
REI3 offers a default index, which works on almost all attribute types, like numbers, dates or names, to quickly find specific data. It is however limited when it comes to larger text values, such as articles.
When text attribute values become too large (more than a few paragraphs), the default index does not work anymore as its not designed to work with large texts. Its also very inefficient to scan for specific characters in a growing number of large texts.
For this situation, REI3 offers a dedicated text index option. A text index does not index every character, but instead breaks down the text content to its components. This gives us full-text search capabilities, which offer very fast, multi-word lookups. To use a text index, just select the option when adding a new index on a relation.
There is however another benefit with text indexes: Language specific lookups. If its possible to know the language of a text, full-text search can also break down words to their stems and remove stop-words. This enables lookups for words of the same stem as well as further improve performance. To enable this option, the relation on which the text attribute is stored, requires a dictionary attribute. This attribute is used to store the language of a text. If a dictionary attribute is used and given a value, lookups take into account specifics of the defined language to better find results.
Triggers
Triggers are an advanced feature, reacting to changed records inside your relations (on creation, update or deletion). They are usually used for complex or event driven business logic.
A trigger calls a pre-existing backend function and executes the code inside of it. To create a trigger, you start with a backend function with the type 'trigger'. Once created, you can create a trigger event for the backend function on any relation inside the current application or any that your application builds on. You can also create a trigger from inside a relation, by selecting an existing trigger backend function.
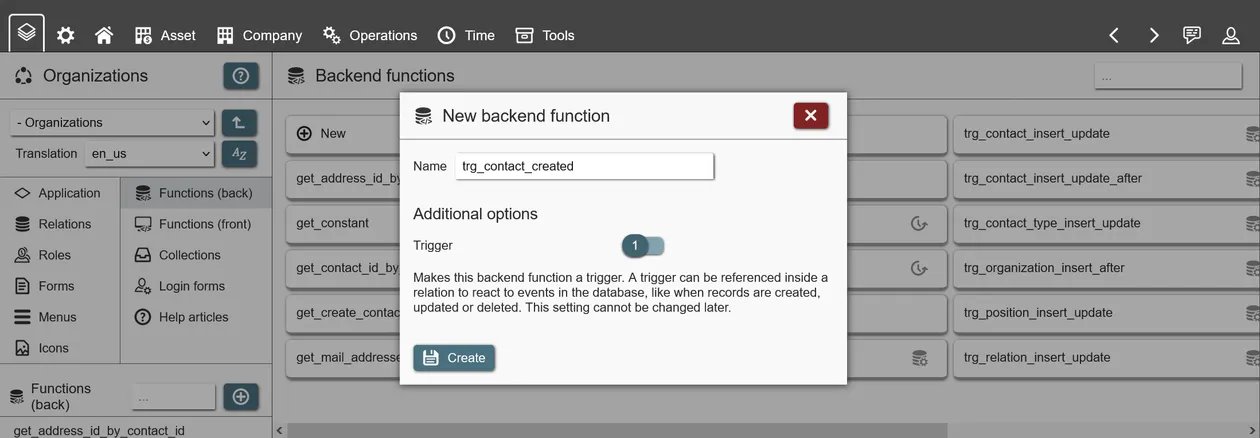
Multiple options exist for triggers:
- ON INSERT/UPDATE/DELETE: Event on the relation that the trigger reacts to.
- EACH ROW: Trigger executes function for each affected record or once after all records from a relation are processed. If set for EACH ROW, NEW/OLD can be used inside the trigger function to reference or update the record values, depending on the event.
- INSERT: When a new record is created, NEW will contain all values of the new record. You can access it by using regular function placeholders for attributes, as in:
NEW.(lsw_organizations.contact.display_name). You can then work with these values or overwrite them, as in:NEW.(lsw_organizations.contact.display_name) := 'My_value';- these changes will directly be reflected in your records. Make sure to end your function withRETURN NEW;. - UPDATE: When a record is updated, NEW will contain all values after the update, while OLD contains all values before the update. Just like with INSERT, make sure to end your function with
RETURN NEW;. - DELETE: When a record is deleted, OLD will contain all values before the deletion. Make sure to end your function with
RETURN OLD;.
- INSERT: When a new record is created, NEW will contain all values of the new record. You can access it by using regular function placeholders for attributes, as in:
- BEFORE/AFTER: Trigger executes function before or after the specified event has occurred. BEFORE can be used to simply overwrite record values or log changes elsewhere, while AFTER can be useful to work with changes over multiple relations ('see DEFERRED').
- DEFERRED: If enabled, triggers are executed after changes to all relations are done. This means that when multiple relations are updated (like on joined relations on a data form), you can work with the final values of all records inside a relationship. Since each trigger only reacts to events for its own relation, NEW/OLD cannot contain values of connected records; in this case you need to use SELECT/UPDATE/DELETE to lookup or affect other record values.
- Condition: A SQL condition, must return true for the trigger to execute the function.
- Execute: The function to execute. Must be a function that returns 'trigger'.
You can also execute a single trigger function for multiple events. With the variable TG_OP you can check, which event occurred, such as:
IF TG_OP = 'INSERT'
THEN my_var := 123;
ELSE my_var := 456;
END IF;For more details about triggers, you can lookup the PostgreSQL trigger documentation.
Policies
A relation policy can limit what specific records are accessible to a logged in user via their role memberships. This is done by using backend functions that serve as filter for specific actions. While forms, data display fields and other frontend elements can also filter records, relation policies are applied globally and cannot be circumvented by changing the frontend.
A policy can be set for different actions, these are:
- Select: Users can only see records based on the results of the policy; they have no way of knowing whether or how many other records exist.
- Update: Users can only change values of records based on the results of the policy.
- Delete: Users can only delete records based on the results of the policy.
Depending on the action, the frontend will either not show records (no select), disable inputs (select but no update) or block record deletion (no delete). Regardless of the frontend, relation policies will always be enforced on the backend.
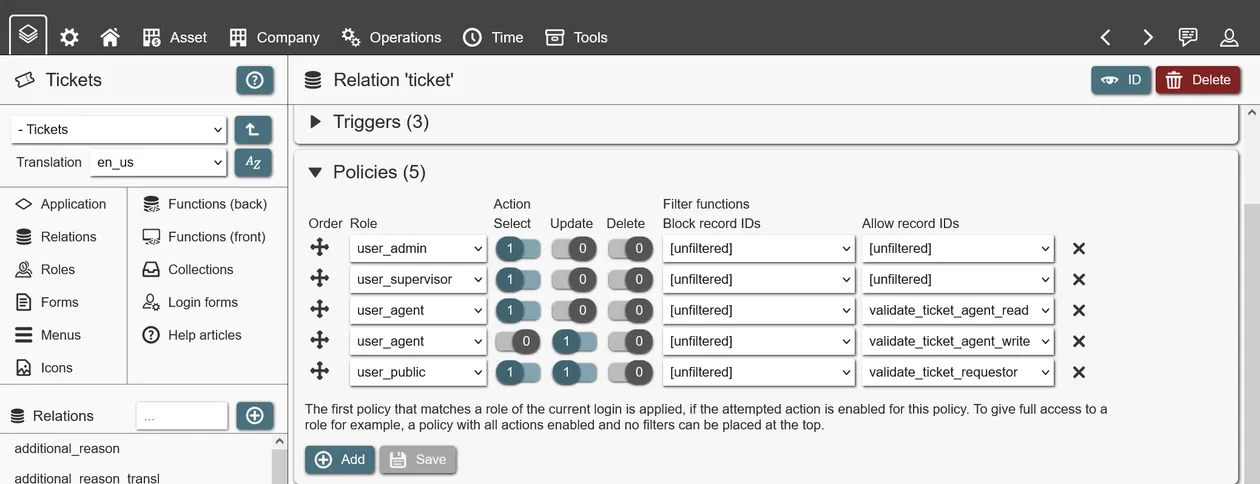
To create a policy, a role must be connected to at least one action. An 'allow' (whitelist) or 'block' (blacklist) filter function is used to define which records should be accessible. A filter function is a backend function that returns an array of record IDs (as in 'INTEGER[]' or 'bigint ARRAY'); the record IDs must match the relation for which the policy is defined. With the help of instance functions, such as 'has_role()' or 'get_user_id()', filter functions limit what records are accessible based on the currently logged in user.
Polices have a defined order. The first policy matching the attempted action of the logged in user with the selected role, is applied. If the user has multiple roles, only the first matching policy is applied. If full access is desired, a role can be assigned all actions and both filter functions kept empty (e. g. 'unfiltered'). If no policy is matched, full access is also granted.
Change logs
When data is changed in REI3 you can choose to automatically keep copies of these changes. These change retention settings are defined for relations. If nothing is set, no data changes are kept. Every relation has 2 settings for defining data change retention:
- Keep a number of changes. Change log keeps at least the specified amount of changes.
- Keep changes for a number of days. Change log keeps all changes for the specified amount of days.
A system task regularly deletes older changes, when the retention settings are satisfied. If both settings are used (number and days of changes), the more conservative setting wins. Example: 30 changes should be kept for 90 days. If there are more than 30 changes, they are all still being kept if they occurred within the last 90 days. If there are changes after 90 days, but still less than 30, they are also being kept.
Changes are visible to users in forms that access corresponding relations via the change log window. This will show all changes corresponding to joined relations (see Queries), but only for attributes that are accessible to the user via data input fields. If a user has access to a data field, and changes are available, they will be visible without further permissions being required.
Roles and access management
Roles are used to control what a user can see and do in an application. Roles control:
- Data access: What access to data structures, e. g. relations and attributes, a role member has.
- Menus: Which menus are visible to a role member.
- Collections: Which collections are retrieved for a role member.
- Search bars: Which search bars are available to a role member.
- Widgets: Which widgets are available to a role member.
- APIs: Which APIs are available to a role member.
- Client events: Which client events are available to a role member.
- Policies: What access a role member has to specific records. Defined in relation policies.
- Start form: Which form is shown when a role members opens an application. Defined for the application.
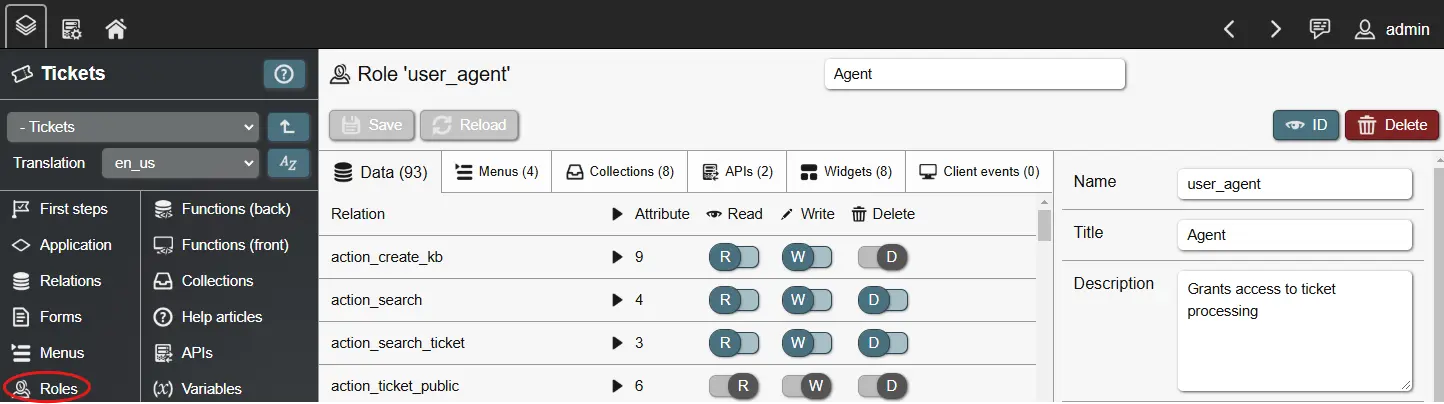
Roles in REI3 are cumulative; the more roles a user has, the more access is available. There is no 'deny' option; when you need to deny a group of users access, you remove the corresponding access from the role and create a second one, granting this specific access.
When creating a role, you need to choose a unique role name within your application. Titles, descriptions and role types serve to explain the role to administrators of REI3 instances as they will be shown in the admin UI. The role type is purely descriptive and only serves to make role assignment quicker.
Roles can be members of other roles. This enables access inheritance with no fixed limit on how many levels of inheritance are allowed. A user logging in, receives access following assigned roles and the memberships of these roles (and the memberships of those roles, and so on).
The role 'everyone' is pre-defined and available in all applications. Anything assigned to this role is assigned to all users that can login into REI3, regardless of what other roles they might have. This role should primarily be used during development or when access does not need to be limited at all. Before an application is released into production, assigned permissions to 'everyone' should be moved to other roles, based on required access.
When applications build on other applications usually some access to the other application´s data is necessary. This is solved by making your roles members of roles from other applications. In many cases data access is desired but users from one application should not see user interfaces from the other; this is addressed by creating 'data only' roles with no assigned menus, widgets or search bars.
Lastly, the option 'assignable' controls whether a role is directly assignable to a user. If set to 'false' the role is hidden in the admin UI and can only be assigned indirectly via membership of other roles. This can be useful for 'data only' roles or for complex role hierarchies.
Presentation and user interfaces
Besides managing data, most systems require some kind of frontend. For this purpose, REI3 includes forms to display and manipulate data and menus to navigate your application.
Forms
Forms serve to display and manipulate data. They can also be used to execute actions or react to user inputs via frontend functions.
When creating a form, you can specify the following:
- Icon: An icon representing the form. Shown in the form header, if not overwritten by a menu entry.
- Name: A unique name in your application. Only for your own reference, not shown to users.
- Title: The translated title of your form (see Translations). Shown to users. Can be overwritten by a menu entry.
- No data actions: Option to remove all data actions (new, save, delete) from a data form. Useful when working with records without wanting to make changes to them, like as input for frontend functions.
- Open preset: Option to open a specific preset record when opening a form. Useful for central configuration records.
- Set field focus on load: To place focus on a specific data input field when the form loads.
Once created, you can start designing your form. Generally, forms can be separated into two types:
- Data: You define a query to create, update or delete relation records (inside the form content tab). This will give you access to attribute input fields from the selected and joined relations.
- Non-data: You do not define a query. This type of forms usually serve purposes other than record manipulation. Some examples:
- Showing a full page data display field to view and navigate to records.
- Showing a dashboard of multiple lists and buttons to reach different parts of your application.
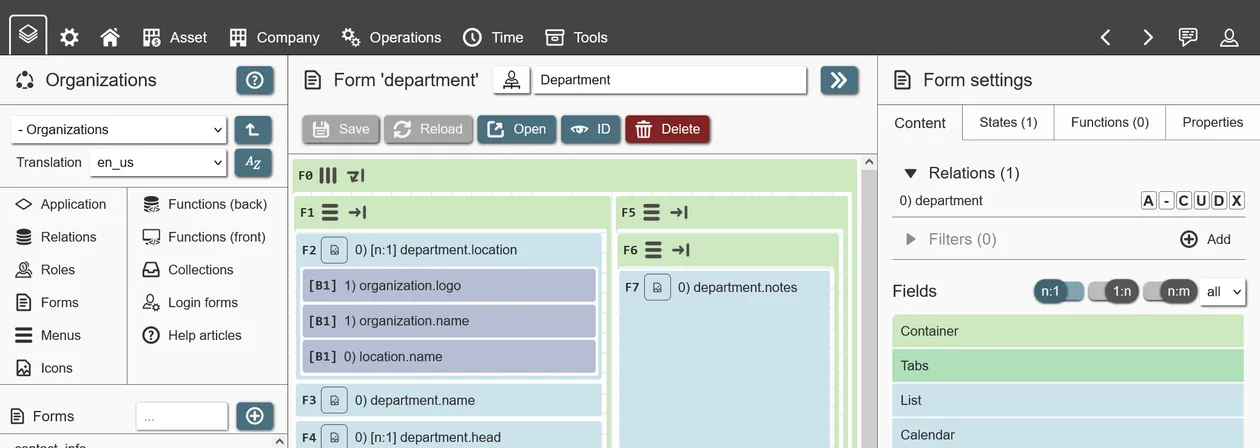
Forms are designed by adding and configuring fields. Fields serve to create layouts, manipulate data, execute actions and more. Available fields are shown in the sidebar, depending on what the form has access to. These types of fields exist:
- Container: These construct the layout of your form. Containers 'contain' other fields, including other containers to create simple or complex layouts.
- Tabs: A field consisting of one or more tabs, which then contain other fields. Useful to separate UI elements, hide seldom used fields or improve usability of very large forms. To add layouts inside tab fields, you can use container fields.
- Data display field: A field showing records from other relations. Can be used to show or create associated/child records. Also often used as jumping off point to other forms. Depending on the chosen type, records can be presented as list, calendar, Gantt plan, Kanban board and so on.
- Label: Can either show a simple line of text with a fixed size and icon (useful for headings) or any HTML value.
- Button: Actions that a user can execute (see Button fields).
- Data input (data forms only): Dependent on the defined query, attribute input fields are available to view and manipulate record values. They are labeled by the relation index, the relation name and the attribute name, as in '0 employee.forename'. Depending on the attribute type, fields will behave differently and offer different settings.
- Data input by referring relationship: Like data fields but for N:1 & N:M relationships. With these fields users can see and manipulate multiple relationship references at once. Depending on the field settings, they can be displayed as multi-input dropdowns or checkboxes.
To summarize: A form can handle a relation record by defining a query (data) or not (non-data). It consists entirely of fields, with container fields being used to create a layout. To view/manipulate records, attribute input fields are available for selected relations (see Queries), while many settings exist to customize these (see Field settings).
Form layouts
Form layouts in REI3 are based on the CSS standard 'Flexbox'. Every container field in REI3 is a flexbox container, which configures its own size as well as layout characteristics for its children.
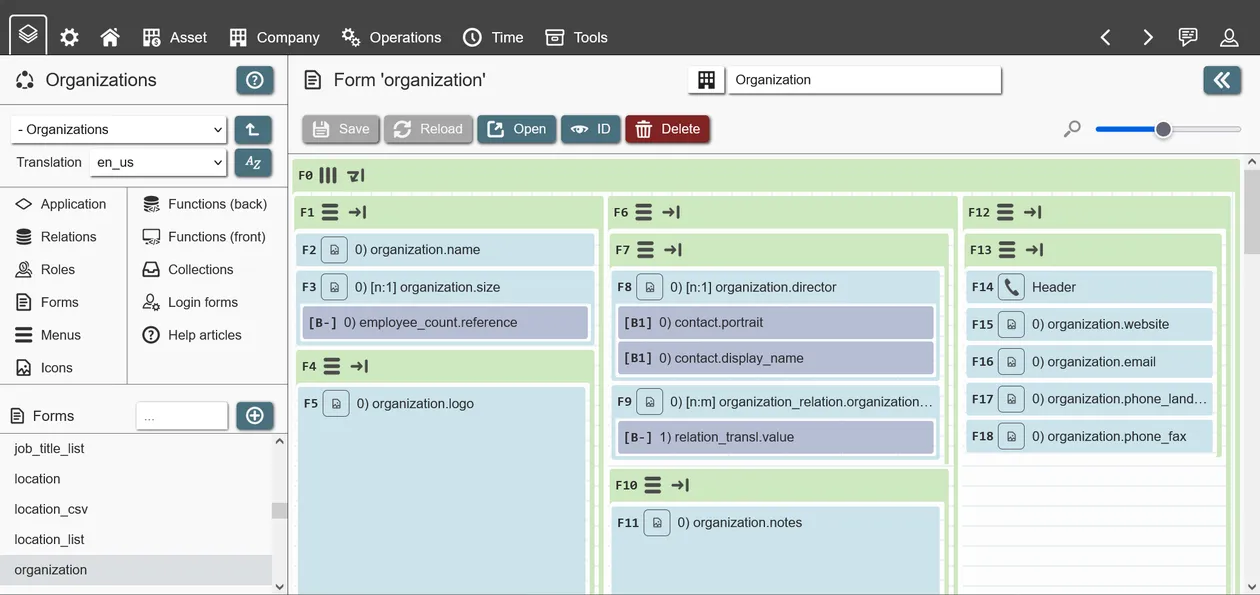
The most important concept is the flex flow. Every container decides, whether its contained fields (children) will 'flow' in a row (from left to right) or in a column (from top to bottom). In addition to the flow direction, the container decides whether its children will 'wrap', meaning they will move into a new row or column if the available space is insufficient. Disabling wrapping will result in fields needing to shrink their sizes or expand their parents size resulting in compact fields or scrolling, depending on the parents configuration.
To create specific layouts, row and column containers are usually mixed. An example: To create a form with 3 columns next to each other, with multiple fields in each column, the following containers can be used:
- 1 parent Container with a 'row' layout, containing 3 child containers, 1 for each column. Wrapping is enabled so that if the form is too small, the 3 column containers move underneath each other to properly display their content without horizontal scrolling.
- 3 child containers each having a 'column' layout, meaning that their children fields are displayed underneath each other. Wrapping is disabled, as forms are usually designed to be scrolled vertically.
If you are inexperienced with Flexbox, it is best to play around with containers in the form builder. Basically any layout can be created by mixing container configurations. Important to note: Non-container fields do not have layout configuration. If you need to specifically change the layout of a single non-container field (its size for example), you place your single field inside a new container field and change the container layout. This is done to keep layout options and complexity to container fields only.
When editing a container field, the following options are available:
- Show in mobile view: If disabled, this field (and its children) are not visible when accessing REI3 via a mobile device.
- Base size: Initial size of the container (width if inside row layout, height if inside column layout) in pixels. Is affected by its grow/shrink factors (see below).
- Grow/shrink factor: A number compared between all children inside the same container. A field with a factor of 3 will grow/shrink 3 times more than a field with a factor of 1. Growing and shrinking occur when more/less space is available than the field requires.
- Grows/shrinks to: Percentage value of the maximum/minimum size (from the base size) a container will grow/shrink to. Ignored if the base size is set to 'auto'.
- Wrap content: Move children fields to a new line (row/column) if space is insufficient. If disabled, fields are shrunk, parents expanded or scrolling used, depending on the configuration of the parent and its available space.
- Direction: Place children in a row (left-to-right) or column (top-to-bottom) layout.
- Justify content: Defines the alignment of children on the main axis (row: x, column: y).
- Align items: Defines the alignment of children on the cross axis (row: y, column: x).
- Align content: Only relevant if a row or column has more than one line (wrapping enabled). Defines the alignment of children with the lines.
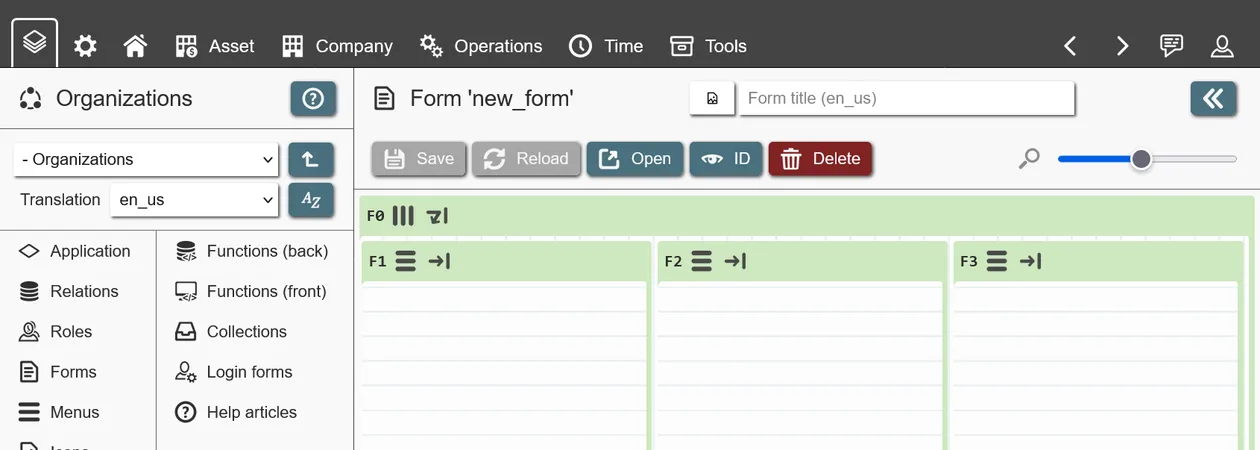
Field settings
Depending on the field content, different options are available:
- State: Available to all fields, default state of field.
- Hidden: Field is hidden. Useful in combination with form states, showing fields only if certain conditions are met.
- Default: Field is shown. Data fields are automatically set to 'readonly' if the user is missing permissions and to 'required' if the data field attribute is not nullable.
- Optional: Data field only. Input is always optional.
- Readonly: Data field only. Input is always readonly.
- Required: Data field only. Input is always required. Form will disallow saving while this field´s input is empty.
- Data fields: Non-relationships
- Display: Presentation options, available depending on attribute type.
- All attribute types
- Default: Default presentation option. Single line input for text attributes, file input for files attribute and so on.
- Text attributes
- Email / phone / URL: Similar to the default input, a single text line is given for input. A link icon is shown, which can be clicked to 'open' the input value according to its type (browser for URL, mail program for email, etc.). The validity of the input is not checked - if validation is needed, RegEx validation can be used (field option 'Validate with RegEx').
- Password: Field input is shown as a password field, hiding the input by default. A button to make the password visible is offered inside the field. Using this display option does not encrypt any data by itself; to safely store sensitive data, use end-to-end encryption.
- Integer attributes
- Rating: Field input displays a number of icons with the amount of icons being controlled by the max. value setting (up to 10). This presentation option is useful for rating of performance or priority - anything that can be assigned a 1-X scale. If no icon is selected for the attribute and/or overwritten by the field, a star icon is used.
- Value slider: Field input is a slider, movable from min. to max. defined values.
- All attribute types
- Default value: Default value, placed in the field input when a new record is being shown.
- Min./max. value/length: Minimum/maximum length/value of data depending on attribute type.
- Text attributes: Count of characters (text length).
- Integer/number attributes: Number value.
- Files: Number of files allowed.
- Alignment: Relevant for input fields with a simple text input. Defines whether the input should be aligned to the left or right. Useful for numeric inputs with a fixed length.
- Monospace: Text inside the field input will use a monospace font, which results in all characters having the same length. This, together with defined lengths before and after the decimal point on the attribute, can be useful for numeric inputs.
- Clipboard: Offers a button inside the field to copy the current value to the users clipboard.
- Validate with RegEx: Regular expression that field input must match to be considered valid.
- Display: Presentation options, available depending on attribute type.
- Data fields: Relationships
- Category selector: Instead of dropdown (default), field input becomes a radio menu (if 1:1/N:1) or checkbox input (1:N/N:M).
- Auto select records: For a new record, automatically select the first x (if positive value) or last x (if negative value) records that would appear in input dropdown. Can be used together with query filters and sorting to pre-select specific records (see Queries).
- Default preset(s): If relationship target contains presets, you can select which of these are to be set by default. Can be one or multiple presets (if 1:N/N:M).
- Open record: In addition to selection of records, relationship inputs can be used to open existing or create new records with. By choosing a form that handles this kind of record, a user can quickly open or create new records. Form states can be used to control, whether records can be opened/created the relationship input field.
- Data fields: All
- Default value(s) from collection: Use collection value(s) as field default value(s). If the data field contains a single value (like a text attribute) the first value from the collection will be used; for single-value fields, collections should be used that only return a single record. Data fields with multiple values (1:N/N:M relationship inputs) use all collection values as input.
- Function on value change: Executes a frontend function when the field value changes.
- Button fields
- Open form: Navigates to or opens a form as pop-up window.
- Function on click: Executes a frontend function when the button is triggered.
- Data display fields
Data display fields
These fields serve to present and/or make accessible data from multiple records. Currently, these data display fields exist:
- List: A regular list of records. Has many options for data presentation and access.
- Calendar: Presents time-related records on different calendar views (month, full week, etc.). Very useful for viewing, creating or updating time-based records.
- Gantt: Presents time-related records as a Gantt plan, grouped by associated entities (owners, states, etc.).
- Kanban: Presents records as Kanban cards, with the option to drag&drop them between Kanban columns (and optionally rows) for reassignment to things like people or states.
- Chart: Presents record values as charts or diagrams.
In general, all data display fields can be placed on any form. When placed on a data form, which handles creation of specific records, they can serve to display related data (child or associated records). They can also be used to navigate to other forms/records.
When placing a single data display field on a form by itself, it becomes a full page field. This not only makes the field more usable (more available space) but also enables full page navigation and hotkeys. Most often, full page fields are used as starting points to access top-level records, with child-records being shown inside data forms with smaller data display fields.
Data display fields use queries to access data - these can be configured in the field content tab. Once the query has been defined with at least one relation, columns can be added; column values are then shown as part of the field.
Depending on the type of data display field, different field options are available:
- Lists
- Display: Table or card layout. The default view is the table; showing records, one per row, with columns separating the record values. The card view is an alternative that shows each record as a separate card, with values being placed vertically inside it.
- Result count: The default page result limit. If more results are available, the user needs to navigate between pages. Can be overwritten by the user.
- CSV import/export
- Quick filter: A simple text box with which a user can filter the entire list. Inefficient, as all visible attribute values are being looked through. Advisable only for lists handling limited data or when all shown attributes are indexed. Useful for sub lists that are already being filtered by a currently open form record.
- Calendar/Gantt
- Date from/to: Attributes that define the date/time of shown records on the calendar / Gantt. Given attribute values must be date or datetime and must not be mixed. If date values are used, only full day entries are shown on the calendar; if datetime values are used, both full day as well as non-full day entries are displayed.
- Color: (Optional) attribute value that is used to color the date entries.
- Calendar
- iCAL subscriptions: This feature allows users to subscribe to a calendar with their personal devices. If enabled, how far the calendar data is provided (before/after the current date), can be defined in days.
- Default view / users can change view: Controls what calendar view is shown as default and whether or not users can change this setting for themselves.
- Gantt
- Gantt interval / interval toggle: Controls what Gantt interval is used by default (days/hours) and whether users can change this setting for themselves.
- Gantt fields in general require some data to be used for grouping, because each line of a Gantt plan displays date values of a specific entity. This can be a person, a task, project or whatever else. Gantt fields automatically use all values within the first column batch to populate the Gantt group - so multiple columns can be used to describe the entity of a Gantt line. Example: Portrait, forename + surename of a task owner.
Options, available to all data display fields:
- Open form: To create, open or update a record.
- From relation: Defines, which record to handle - based on the chosen relation in the field´s query.
- Form: The form opened for a record. The form must have the record´s relation (s. 'from relation' above), as its base relation. Whether or not options to create a new or open an existing record are shown, follows the relation settings, defined in the query of the data display field.
- Opens as: Whether the form is opened by navigating the browser, as a floating window or within the current data display field as a sub form.
- Establish relationship with new records: Applies a record ID of the current form, to an input field on the opened form. Usually used to create child records, by pre-filling relationship input fields with the record ID of the parent record, currently being edited.
- Open form (bulk editing): To update multiple records at once. Basically has the same options as the regular 'open form'. Can only be used to update records - not to view, create or delete them.
Every data display field can use simple or complex filters to limit the amount of records being shown. Different filter types exist that either completely remove records or can be set by users (filter sets). Setting filters on data display fields only affect the current field. To filter records regardless of where they are being accessed, policies can be used.
Lastly, there are chart fields. These use the powerful open source visualization library echarts. REI3 ships with the full version of echarts, in theory supporting all available charts (see examples). There are however some implementation details to be aware of:
- The Builder does not offer visual configuration of all echart options - there is a huge number of them and they are expanded with new releases. Instead application authors can edit the echarts 'options' object, which gives access to basically all configuration options (see echarts documentation).
- For some simple chart types (bar, line, pie, scatter), the Builder offers some UI inputs. For more complicated types (like boxplots, funnel, etc.), the 'options' object can freely be used (see series). Legends, styles and many other elements can be configured this way. If the 'options' object is used, the Builder inputs can safely be ignored - they only help to fill the object initially or when using simple charts.
- REI3 fills in the dataset source of the 'option' object with an array of results from the chart field query. Every array element is itself an array of values, representing all chart columns in the selected order. When defining a chart, the dataset source is accessed by choosing the value index (0=first column, 1=second, and so on) in the series configuration.
- When using the 'time' axis type, the column display should be set to a time type (either 'date time', 'date' or 'time'); this will cause REI3 to automatically convert time values for echarts to properly display. If the display type is set to 'standard', the unix timestamps are used by echarts (unix timestamps are the native format of time & date storage in REI3, see date and time management).
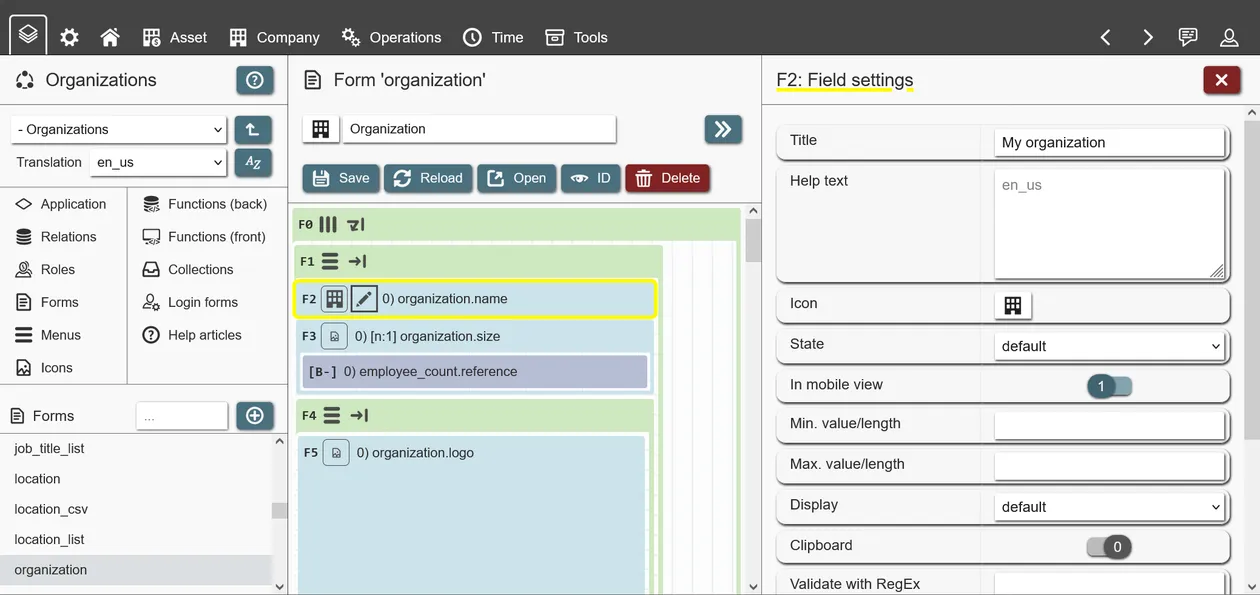
Form states
Form states serve to change the behavior of fields, form actions and tabs; this is done by applying effects based on form state conditions. Multiple form states can be used and will work in parallel.
Similar to query filters having one or many filter lines, form states have conditions. Each condition contains a connector (AND/OR), comparison criteria (field value, user role, etc.), an operator (equals, greater than, etc.) as well as brackets to facility grouped comparisons.
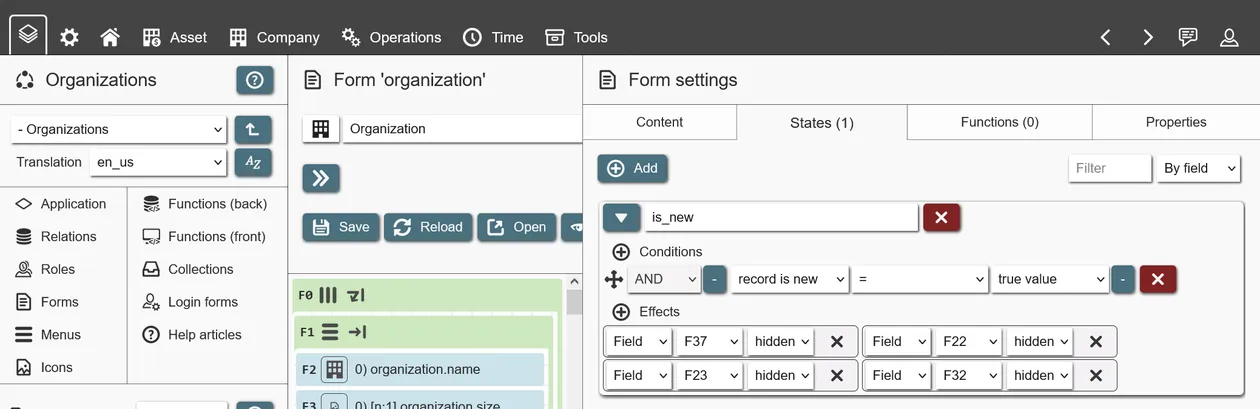
Many condition criteria are available:
- Data
- Collection value: Value(s) of the selected collection. Most comparison operators (=, <, >, etc.) deal with single values (e. g. X is larger than Z) - in these cases the first collection record value is used, so it should be a collection that only returns a single record. Some operators deal with arrays or multiple values (ANY, ALL) - these work against all record values of a collection.
- Preset record ID: Integer ID of the record that has been created from a preset. Only protected presets can be selected, as unprotected presets can be deleted.
- Fixed value: A fixed text value to compare against.
- True value. Always TRUE - used to compare against other TRUE values.
- Variable value. The current value of the selected variable.
- Current form
- Form has unsaved changes: TRUE/FALSE depending on whether the current form has any unsaved changes.
- Field value: Data field value on the current form.
- Field changed: TRUE/FALSE depending on whether the current field value is different to its original value. When the current record is new, the previous state is either empty (NULL) or the defined default value for the field. If the record is not new, the previous state is the field value that the record was saved with last.
- Field valid: TRUE/FALSE depending on whether the current field value is considered valid. Invalid field values are for example text characters in number inputs. A field is also invalid if a required input is currently empty.
- Record ID: Integer ID of the currently handled record from a data form.
- Record is new: TRUE if record being handled by the current data form is new.
- Logged in user
- User language code: The selected 5-letter language-code ('de_de', 'en_us', etc.) of the logged in user. Can be used to join relations for translating user definable records and then filter these according to the user language.
- User ID: Integer ID of the logged in user. Is used to filter relations with connection to a user. Useful for employee, customer, agent or other person-based records.
- User has role: TRUE if the currently logged in user has the selected role (directly assigned or inherited).
When conditions of a form state are met, its effects are applied to specified fields. Currently available effects are:
- Hidden: Available for all field types. If set, field is not shown. If field is a container or tab, all its children are hidden as well.
- Default: Field is managed automatically. If it is an attribute input field and not set to 'nullable', it is shown as 'required'. If the user is missing write permissions to the underlying attribute or record (see relation policies), it is shown as 'readonly'.
- Optional: Only attribute input fields. Field is optional.
- Readonly: Only attribute input fields, buttons or variables. Field is readonly.
- Required: Only attribute input fields. Field is writable and required.
If multiple states would apply to the same field the last one is used. Form states are executed in order of their description, so numbered prefixes can be used to achieve a desired state execution order.
Form actions
With form actions, authors can place important actions in a standardized location - this is in the form action bar, next to the record edit actions (new, save, etc.). Form actions work similar to buttons, executing a frontend function when activated. They can also be controlled via form states, managing whether they are visible at all or just readonly.
Queries
To show or manipulate data, REI3 components (like forms, data display fields or APIs) need to know how to access data. This is done by defining data access queries or 'queries' for short. Queries control how data is retrieved and (if desired) updated or deleted.
To define a query, you start by selecting a relation - this is the 'base relation' or relation index 0. A relation index is a number, that uniquely identifies a specific relation within a query. Once a base relation is set, we can connect or 'join' multiple relations if they are linked with relationship attributes, with each receiving a unique index number.
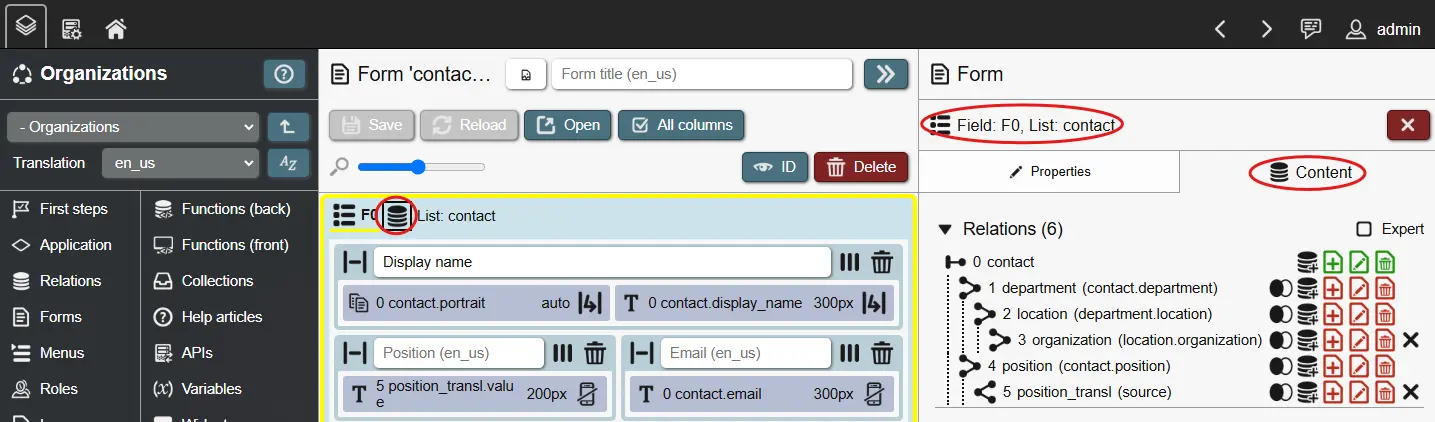
Relation index numbers are important, because relationships can be circular (an 'employee' is part of a 'department', which has a leader that is also an 'employee') or can be a self-reference (an 'employee' can substitute another 'employee'). Because of this, the same relation can be joined multiple times, but would contain different records (due to different relationships). With relation indexes, we can reference the correct records when placing input fields or displaying record data.
When joining relations with each other, there a couple of options:
- Join type (F)ull, (I)nner, (L)eft or (R)ight. Primarily useful in data display fields. These values define, how the join handles its relationship. An inner join, for example, only receives records for a relation, if the relationship partner is valid, while a left join still shows the relation record even with no valid relationship partner. These settings directly follow common relational database systems; for more information please lookup 'SQL joins' from external resources.
- Record handling: The following options define how records of specific relations are handled. Relation 0 is the most important one as its record is the base that is opened on forms and used as base in data display fields. Joined records from other relations are available as well and are created/updated/deleted based on the defined options below.
- (C)reate: If set, a record can be created by a form or, if set for data display fields, new records can be created when a form is defined.
- (U)pdate: It set, a record can be changed by a form or, if set for data display fields, records can be updated when a form is defined. Some data display fields (like Kanban) can also live update record values via drag&drop.
- (D)elete: If set, a record can be deleted by a form or, if set for data display fields, an option to delete records is shown.
- The record handling options directly affect the specified relation. Example: If relation 0 is set to (C)reate and a joined relation 1 is not, only the record for relation 0 can be created and all input fields for relation 1 are presented as 'read only' on the form. The same with (U)pdate and (D)elete: Only records from relations with these enabled can be changed when the base record (relation 0) is updated or deleted.
Queries can be defined for the following entities:
- Forms: What records are handled on this data form. A form manipulates the record of its base relation (index 0), together with the records of all joined relations.
- APIs: What data can be retrieved, created, updated or deleted.
- Collections: What data is available to the collection.
- Variables: What data is available to the variable if its used as a relationship input field.
- Data display fields: What records are shown. Most often used to display and then open records on a data form to make changes to these records. These fields show all available records from the chosen relations within the defined filter criteria.
- Sub queries: These can be used as filter criteria or as column values in fields. They return a single attribute value that can be used as condition or to display values, like aggregations in columns.
Besides selecting relations, if more than one record is to be handled, sorting can be applied to the results. Sorting is applied to the selected attribute in the defined order; when multiple sorting options are defined, results are sorted by the first, then the second and so on.
Query filters
Query filters serve to filter query results. They are used by frontend components like forms, data display fields, data input fields showing relationship attributes, collections and so on.
Filters are made up from filter lines. Each line contains an AND/OR connector (first line is always AND), two filter criteria (to compare them) and a comparison operator (equals, greater than, etc.). Additionally, filter lines can be grouped with left and right brackets to create more complex AND/OR conditions.
Query filters can be defined in two ways:
- (Regular) filters: Automatically applied on any data access. Depending on filter conditions, different data can be shown in different contexts (logged in user, role membership, active interface language, and so on).
- Filter sets: A named set of filter conditions, from which a user can choose from to customize the output. Multiple filter sets can be defined for a query. If at least 2 sets are defined, users can choose between them. This enables result subsets in lists (like only 'active', 'closed' or 'records in recycle bin') and in input dropdowns ('show only colleagues in my department' or 'in entire company'). The first filter set is active by default. If multiple sets are desired but everything should be shown by default, create the first filter set without any filter lines.
The full list of filter criteria:
- Data
- Attribute value: Current record value for the specified attribute. Not affected by changes on a form until they were saved.
- Collection value: Value(s) of the selected collection. Most comparison operators (=, <, >, etc.) deal with single values (e. g. XY is larger than Z) - in these cases the first collection record value is used, so it should be a collection that only returns a single record. Some operators deal with arrays or multiple values (ANY, ALL) - these work against all record values of a collection.
- Preset record ID: Integer ID of the record that has been created from a preset. Only protected presets can be selected, as unprotected presets can be deleted.
- Sub query: The value from a sub query. Value type depends on the selected attribute from the defined sub query.
- Fixed value: A fixed text or number value to compare against.
- True value. Always TRUE - used to compare against other TRUE values.
- Variable value. The current value of the selected variable. Only available in frontend facing queries (not in APIs or collections);
- Current form (only if query is in context of a form)
- Form has unsaved changes: TRUE/FALSE depending on whether the current form has any unsaved changes.
- Field value: Data field value on the current form.
- Field changed: TRUE/FALSE depending on whether the current field value is different to its original value. When the current record is new, the previous state is either empty (NULL) or the defined default value for the field. If the record is not new, the previous state is the field value that the record was saved with last.
- Field valid: TRUE/FALSE depending on whether the current field value is considered valid. Invalid field values are for example text characters in number inputs. A field is also invalid if a required input is currently empty.
- JavaScript expression: The return value of the given JavaScript expression. The expression is executed as a function when the filter criteria is being checked. Useful for simple date calculations (like getting the previous year) or similar tasks. Should not be used to access anything outside the function itself.
- Record ID: Integer ID of the currently handled record from a data form.
- Record is new: TRUE if record being handled by the current data form is new.
- Logged in user
- User language code: The selected 5-letter language-code ('de_de', 'en_us', etc.) of the logged in user. Can be used to join relations for translating user definable records and then filter these according to the user language.
- User ID: Integer ID of the logged in user. Is used to filter relations with connection to a user. Useful for employee, customer, agent or other person-based records.
- User has role: TRUE if the currently logged in user has the selected role (directly assigned or inherited).
- Current date/time: Current date/time value (depending on selection), offset by a chosen amount of days/hours/minutes/seconds to compare date/time attribute values against. Useful for filtering records that have a specific date within the last 30 days for example.
Since the frontend is running on a users device (e. g. browser), its code can be manipulated and query filters overwritten or removed; to limit access to sensitive data to specific individuals, relation policies can be used to safely filter data on the backend.
Columns
Columns are used to choose data to be retrieved from a query when working with things like data display fields, APIs or collections.
There are two types of columns:
- Attribute columns: These are available automatically, based on the selected relations from the query. They display the value for the selected attribute for each record.
- Sub query columns: These can show data outside the main query. Sub queries can show data from any accessible relation, but are usually filtered by attribute values from the main query. By creating corresponding filters on the sub query, aggregation functions can do things like 'show totals' or 'display averages' for sub entities of the current record. Sub queries can use other sub queries to filter themselves and also be used as filters inside the query itself.
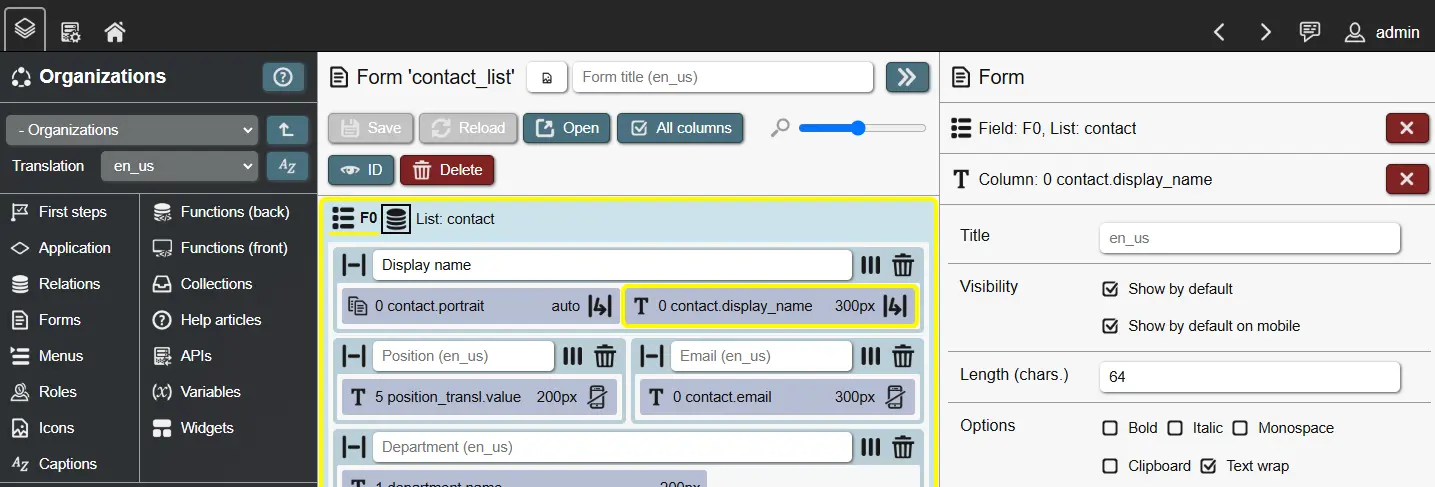
Columns each have a translated title to communicate their content to users. If no title is given, attribute columns can fallback to the attribute title. Besides titles, columns have multiple options:
- Size (pixel): A size in pixel (usually width) that a column attempts to populate. Can be used to limit the size or reserve space for important columns. If text wrapping is disabled, text values are cut off with '...' when they reach the target size or the available space is insufficient (up to a point).
- Length (characters): If set, text values in a column are limited to the specified length. Text values are cut off with '...' when they reach the specified length.
- Text wrap: Text values wrap to a new line when space is insufficient. Can be combined with column size and length settings to control how text is displayed.
- Clipboard: Shows a copy-to-clipboard action inside the column.
- Display: Depending on the attribute type of a column, different display options are available. These serve to specify how to present attribute values.
- Data retrieval: Multiple options exist to configure, how column values are being retrieved.
- Distinct: Useful when joining N:1 or N:M relationships or when using sub queries. Filters out duplicate values for the given column attribute.
- Group by: Records are grouped by the values of the given column attribute. Records with identical values for the grouped attributes are merged; this requires other attribute columns to either be grouped as well or aggregated.
- Aggregate: Use aggregation functions on the given column attribute. Like with 'Group by' this requires other attribute columns to either be grouped or aggregated as well. Aggregate functions follow well-known SQL standards (sums, counts, etc.) - there is one special case however for REI3: 'single record'. This is basically a 'FIRST' aggregation, taking the first available result from the group or aggregation set. 'Single record' exists to allow REI3 to still make a specific record selectable on the current list even with grouping and aggregations combining and merging results; this can be useful when working with complicated joins, but often can be avoided by using sub queries.
Columns can be 'batched' by dragging&dropping a column over another one. Batched columns merge their record values to show a single column instead of multiple ones.
Help articles
Sometimes it becomes necessary to explain concepts, data structures or workflows to application users. Besides titles and small help texts next to input fields, application authors can create help articles that go into more detail. A help article is a piece of richtext that can include descriptions, tables, bullet-point lists, images, external links and so on.
After creating a help article, you can assign it to different places:
- Application help page - a globally accessible documentation for your application.
- Form context help - accessible when a user is on a specific form.
A table of content is automatically generated for the assigned articles in your chosen order. Help articles are translatable and are accessed via the question mark button on all application forms. PDF export is also available for easier viewing or for distributing your application documentation.
Translations
REI3 is a multi language system. By adding translations, you expand the number of available languages that your application can support. However, adding a language requires you to provide translations for affected entities. For some entities, REI3 can use fallbacks - it is however important to test your application thoroughly when adding a new translation.
The following entities are translatable:
- Application title: Shown in the main header and start page of REI3. Configured in the application settings.
- Attribute title: Shown as filter criteria in lists and as fallback for data field & column titles if these are not set.
- Role title & description: Shown in admin UI. Serves to explain role usage to administrators.
- Form title: Shown in form header. Can fallback to menu title if not set and if form is opened via a menu entry.
- Form context help: Shown in the help page if the specific form is open. Serves as contextual help for a form.
- Field title: Shown in form over a field. If it is a data field and has no title, it uses the attribute title as fallback.
- Field help text: Shown in form under a field. Additional context help for how to use a data field.
- Column title: Shown in data display fields. Describes the content of a column. Can fallback to attribute title if not set. If column batches are used, only the title of the first column is used.
- Menu title: Shown in application menu. Can be used as fallback for form titles if these are not set.
- Application help page: Shown in the help page, independent of which form is open.
Every translation is referenced by a five-letter language code, such as 'de_de', 'en_us', and so on. A user can choose one language code as their interface language out of a pool of codes from all installed applications. If your application does not support the user-chosen translation, your defined fallback translation will be shown instead (configurable in the application overview).
You can also use translations for presets or live data. By using the filter criteria 'language code' you can join (see Queries) and filter relations based on the currently active user translation. As an example: You can define preset states for a workflow ('new', 'approved', ...) and create a second relation that serves to translate these states. By using one attribute for the language code and the other for a N:1 relationship to your workflow state, you can add multiple translations for each workflow state. Then you only need to filter to the currently active language code. Many REI3 applications use this method for customizable and translatable state records.
Icons
Icons serve to help users recognize entities or navigate the application in different user interfaces:
- Application: Assigned in application overview (Builder start page). Shown in all places the application itself is referenced (home page, admin panel, Builder).
- Menu: Shown before each menu entry. Also shown before the form title, if no form icon is set and the form is opened by this menu entry.
- Form: Shown before the form title.
- Attribute: Default icon for attribute input, shown if a field is handling attribute data and no other field icon is set.
- Field: Depending on the field type, usually shown before an input.
Icons must be added as PNG files with at most 64kb. The system expects icons to have equal height/width - other ratios are possible but may not be displayed correctly. To achieve non-squared icons, the icon image can use paddings with transparent background.
When Building on applications, you can re-use icons from other applications to refer to foreign entities. Re-using icons can help users to understand what entities are being handled.
Menus
Menus serve to navigate between and inside applications in REI3. Two types of menus exist:
- Main menu: Shown at the top of the page, it serves to navigate between applications.
- The header menu shows the top level of applications as well as a second level of assigned applications. Currently 2 levels are supported.
- It is automatically created by resolving accessible applications for the current user.
- The order can be defined in the application overview (Builder start page) with the default position; this option can be overwritten in a target instance inside the admin panel.
- Application menu: Shown on the left, it serves as primary navigation within an application.
- We recommend to keep the menu hierarchy to at most 3 levels for usability reasons.
- Each menu entry can optionally open a form and/or contain sub menu entries. When sub entries are defined, you can choose whether these entries are shown by default or must be toggled first by opening the parent menu entry.
- The translatable menu title as well as menu icon are applied to an opened form if the form does not define its own title/icon.
- Application menus can also be segregated into tabs, with each tab only being visible if the current user has access to at least 1 menu entry within it. Menu tabs are useful to improve navigation by separating concerns by its content or assigned user role.
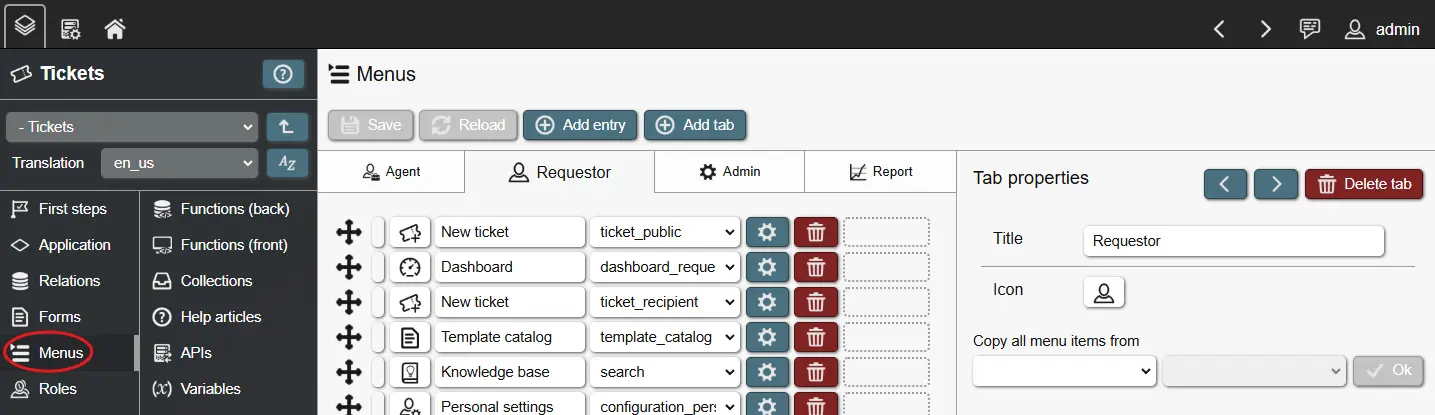
When Building on applications, you can choose to copy the entire menu structure from another application. This is can be useful when you intent to extend another application; you copy the original menu structure, change target forms and add your own, custom menu entries.
Functions
With functions, authors can greatly expand the capabilities of their applications. Basically, functions are executing pre-defined code that the application author prepared. Depending on the type and trigger of the function, they can do different things. In general, REI3 supports 2 function types:
- Frontend functions: Functions that are executed on the 'frontend', e. g. where REI3 is shown to the user. This is the browser that a user opens to access the REI3 application. Frontend functions can run calculations, update input fields, navigate the user to different places and more.
- Backend functions: Functions that are executed on the 'backend', e. g. where REI3 is hosted. This is the server that REI3´s database is run from. Backend functions are used to update data, block invalid inputs, enforce standards and so on.
Frontend functions
Frontend functions execute JavaScript within the user´s browser. How JavaScript works and how it is written is not part of this documentation - please refer to documentation for this language. For examples of how these frontend functions are written, you can install other REI3 applications as reference.
By using frontend functions, applications can execute logic based on frontend events. Some examples:
- User opens a form.
- User saves changes to a record.
- User changes the value of a field.
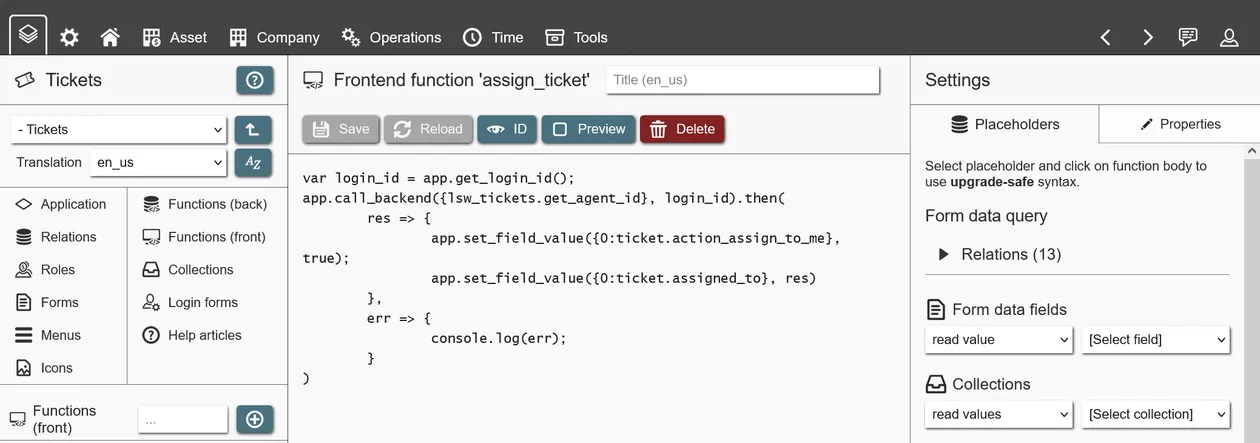
Frontend functions can be used in a 'global context', which means that they can be used and reused throughout the application. This is useful for general helper functions, like validating inputs, logging access or converting values (like time conversions or Markdown to HTML).
You can however also bind a frontend function to a form. This means that it can only be used in the context of the form, but can therefore access form entities like input fields. These functions are usually used for data manipulation/validation purposes.
Within the function code, dynamic placeholders are used to reference other entities like other functions, input fields and so on. Placeholders are important as they protect your function when you make changes to referenced entities.
Frontend functions can also call 'instance functions'; these are functions that can be accessed to interact with the REI3 system directly. Instance function can check a user´s role membership, navigate the user to different places, copy values to the users clipboard, execute backend functions, and more. To learn more about specific instance functions, you can read the contextual help that each function provides.
Backend functions
Backend functions in REI3 are PL/pgSQL functions. PL/pgSQL (Procedural Language/PostgreSQL) is a programming language of the underlying database system that REI3 is running on (PostgreSQL). To learn more about writing PL/pgSQL, please refer to documentation for this language. To start with, you can install other REI3 applications as reference.
By using backend functions, complex data manipulation tasks can be achieved, invalid inputs blocked and standards enforced. Backend functions can be triggered by relation triggers and called from other backend or frontend functions. They can also be regularly executed via schedules.
Within the function code, placeholders are used to reference application entities (relations, attributes and other backend functions). This ensures that changes are upgrade safe: Referenced entities can be renamed safely, while deletion is blocked. Using these placeholders, your functions are protected against breaking changes, while you work on your application.
Backend functions also have access to 'instance functions'. These expose data or features from the REI3 system. They can be used to read configuration settings (like the public hostname), get context information (like the user ID used to access the database) or execute tasks (like sending emails). To learn more about specific instance functions, you can read the contextual help that each function provides.
Variables
Variables are versatile data stores that offer extended capabilities to application authors on the frontend. They can...
- ... be used to store and later access data from within frontend functions.
- ... be used to filter data in things like lists or relationship inputs.
- ... be used as conditions for form states.
- ... be used as inputs on forms, without needing additional attributes.
There are two types of variables:
- Global: A global variable can be set or accessed everywhere in the application. It´s value is persistent as long as the user session is active (eg. user does not close the browser or browser tab). It´s value is not available cross-session, so a user working in two browser tabs can have different values in the same, global variable. Global variables serve to store data, to be used at different places in the application - usually setting values in one form, while using these values in another as defaults.
- Form assigned: A variable assigned to a form, is only available within that form and only as long as the form is open. When the form is closed, like when switching to another form, the variable value will reset to NULL. If the same form is opened twice (eg. a sub form is opened with the same form as content), it´s variable value will be different. Form assigned variables usually serve for actions on the particular form, as additional inputs for filtering other data fields or to update the form state.
All variables have NULL as their starting value, until changed when used as input on a form or set by a frontend function.
APIs
Application authors can create REST APIs to enable creation, retrieval, update or deletion of data from outside the system. APIs use queries to define what can be accessed or manipulated. As with CSV imports and exports, multiple relations can be joined to show or manipulate multiple records and their values at the same time.
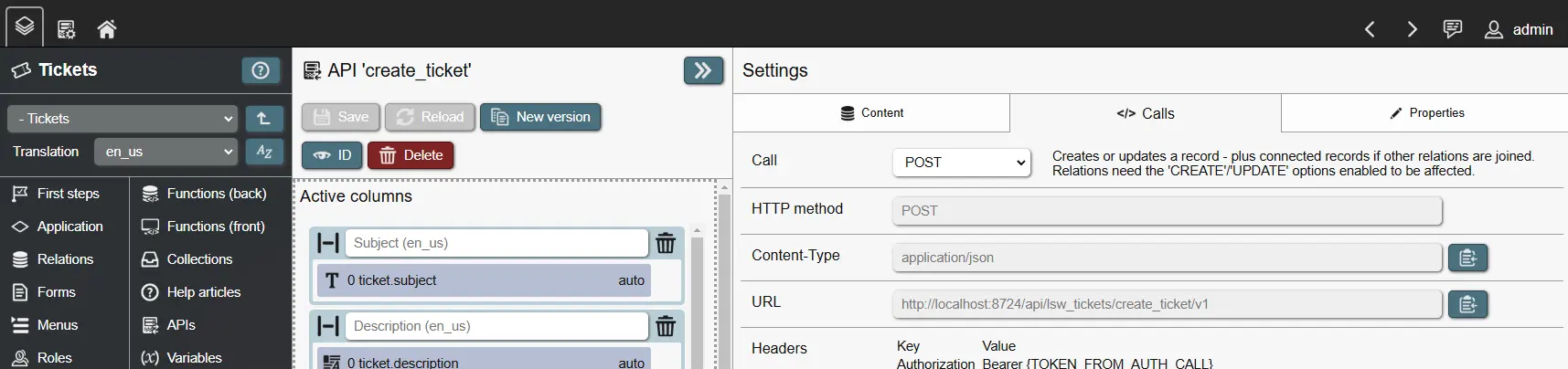
REI3 APIs follow the REST model with the following calls being available:
- POST /api/auth
- GET /api/[application_name]/[api_name]/v[api_version]/[optional_record_id]
- POST /api/[application_name]/[api_name]/v[api_version]
- DELETE /api/[application_name]/[api_name]/v[api_version]/[record_id]
Examples, of how these calls are executed and what they return are shown live inside the API editor. A session token is returned after a successful authentication call (see first call above) and must be included in all successive calls to the API as Bearer Token. The session length follows the maximum user session length set in the REI3 admin interface.
There is no defined limit in the amount of APIs an application can offer - only the API names must be unique within the application. To update an API without breaking existing calls, a new version can be created. The new version will be identical to the previous iteration but have a version counter incremented by one. After applying the desired changes to the new version, both old and new API versions can be used simultaneously. API versions can also be separately deleted when they are no longer needed.
Some considerations:
- APIs use the same roles, policies and so on, that regular users do; the same options to give and restrict access to relations and specific records are therefore available.
- Sub queries can be used in GET calls but will cause POST calls to fail.
- To affect any record on any relation, the corresponding options (CREATE/UPDATE/DELETE) must be enabled for relations in the API query.
- When API calls affect records, relation triggers will fire accordingly. It is not relevant to the system whether changes are made by a user on a form or by an external script/system via API.
- To update existing records or resolve records for joined relations, a record lookup must be defined for each relation in the API query. Record lookups work the same as in CSV imports - any attribute with a unique index can be used to identify a record. The attribute values used as record lookups must be part of the API call.
Calling APIs
REI3 can either serve APIs as a server (s. APIs above) or execute API calls against an external REST server. Calling APIs can be done in either frontend functions or backend functions.
- Calling REST APIs on the frontend is just JavaScript, so any tutorial on how to execute REST calls in JavaScript can be used. Frontend functions can call backend functions to retrieve things like credentials or tokens, stored in relations.
- Calling REST APIs on the backend is done by the REI3 server. When creating new backend functions you can select from a list of templates, which includes examples of REST calls for authentication, sending data with authentication headers and how to handle JSON responses. REST calls are executed asynchronously so a callback function (e. g. another backend function) is used to handle REST responses if needed.
REI3 instances can exchange data, with one instance offering APIs as server with the other calling these APIs as client to receive or update records.
Search bars
With a growing number of relations and applications in a REI3 instance, finding relevant records can take a while. To help users quickly reach relevant records, application authors can define one or more search bars, which are presented to users in a global search interface.
Every search bar has its own query and corresponding filters, to represent a different view on one or many relations in the application. To execute the search, a user provides a single text search input. To apply this input to the search bar query, at least one filter of the type Global search -> User search input should be added; though in many cases, multiple attributes, such as titles, names, descriptions & translations exist, which can be searched through simultaneously via OR condition.
Important: As with all filters, searching through larger data sets requires more time. To speed this up, indexing is recommended. Every attribute used in search bar filters should ideally be indexed. Most attributes, such as short names or numbers can be indexed with the default index option; large texts, such as articles, descriptions, comments and so on, however need a text index. Searching through a text index requires the fulltext search operator; instead of comparing values via =, LIKE or ILIKE, the @@ operator is used (Full-text search -> @@ in the operator dropdown).
Full-text search works differently to regular lookups. They do not compare individual characters, but words or names instead. If the language of a text is defined, they can even break words down to their roots to match words of the same stem - for example, baking as search input would also find results for baked. To define a language, a dictionary attribute is needed on the same relation as the text. It is then filled by either your application or users on a form - it also needs to be included in the text index definition. If the language is not defined, a 'simple' full-text search is executed, which still works the same way but can only work with direct matches - ie. the names or words must match the search input exactly.
Large texts make full-text search a requirement - they allow for fast enough lookups even in very large data sets with large texts. They also enable advanced search features, such as excluding certain words, making sure that words follow each other and so on. More details can be found in all user interfaces that offer full-text search in REI3.
For a search bar to be available to users, it must be assigned to a role.
Collections
A collection is a data store that is available on the frontend, which can be accessed by other frontend elements (like form fields or frontend-functions). It contains data based on a defined query. Depending on the selected columns and filters, a collection will retrieve records and their values.
Collections are retrieved when a user logs into the system and updated when user permissions change; collections can also be updated directly by executing a function. When updating a collection via a frontend function, only the current user will be affected - updating from a backend function can however affect one, many or all users.
Some use cases for collections are:
- As filter criteria in field query filters: When complex or expensive filter criteria are needed in a list view (for example, using multiple conditions and sub queries) it can be very useful to use a collection instead. Collections are retrieved once, expensive lookups are therefore not repeated on every list view. It also removes the need to repeat complex filters on other but similar views; the same collection can be referenced multiple times.
- As user filter for data input fields: Once a collection is defined within a query filter for a data input field, they can be used to offer additional user filter inputs, in which a user can select from existing collection values to filter the current view.
- As default value for data input fields: Collections can also be used as default values for data input fields, like adding values to a relationship input field based on the logged in user´s team memberships. They can also be used to support user configuration options for default inputs.
- As input to a condition of a form state: Form states control how form fields behave - with collections, application authors can use configurations independent of the current record to show/hide/force field inputs depending on global or user-based settings.
- As a notification, shown in the header menu (top header bar): Any collection value can also be shown in the header menu to serve as a notification. Showing values like the number of open requests to be approved, it can also be used to navigate to another form showing data connected to the notification.
- As a notification, shown within a menu entry: Menu entries can reference collection values to show context-relevant data, like counters reflecting the total number of items on a list that the menu entry would show.
Collections can offer any data from the database, to be used on the frontend, regardless of context. They have downsides however. As they are not regularly updated during a user´s session, their values might be outdated. When manipulating data affecting a collection, the user would need to refresh the page or a function would need to trigger a collection update. Depending on the contents of the collection, this limitation may not be relevant or might be easily addressable by rare, event-driven updates.
Widgets
A widget is a small form that application authors can offer to users, which they can then place on their home screens. Widgets are limited in size, with two size settings being available at the moment. They are often used to display important or time sensitive information for users. They can also be used for quick record creation, such as for creating short notes, tasks or starting a shift or timer.
As widgets are just small forms, they offer most of the features of regular forms and can even execute complex functions if required.
Client events
REI3 includes the optional REI3 client software, which can be installed by users from their personal settings. This piece of software runs on Windows, Linux (X11 only) and MacOS. It was created to enable interactions between the REI3 web application (running in a browser or via progressive web app) and the user´s computer.
A client event is a definition of what should occur, when the REI3 client recognizes a specific event. It´s defined in the Builder, in the application setting page and can react to:
- The REI3 client connecting to or disconnecting from the REI3 server. This can be useful for logging or for running data preparation scripts (for things like reporting) based on the connecting user.
- The REI3 client recognizing pressed hotkeys on the user´s computer. This is likely the most common use case for client events, allowing for interactions with REI3, without it needing to be in the foreground.
An example: A REI3 application could define a hotkey client event. When the user presses the hotkey, the REI3 client sends the contents of the clipboard to a frontend function, which looks up relevant data inside the REI3 application and opens a corresponding form. This way, users could copy some text like an invoice number or email address and push a hotkey to find corresponding data inside REI3.
Each client event can execute either a back- or frontend function and can then provide one or more arguments. These can be things like the currently open window title or the contents of the user´s clipboard.
When using frontend functions, an active REI3 session must be running on the same computer as the REI3 client - events are only forwarded to the same origin point. Backend functions directly interact with the REI3 server, only requiring that the REI3 client is connected to it.
Hotkeys for client events must be enabled by each individual user in their personal settings and can be re-assigned there as well.
End-to-end encryption
Encryption can be used to protect sensitive data. Various forms of encryption exist to address different scenarios and risk levels. End-to-end encryption (or E2EE) is especially useful as it protects data whether or not the system is running and independent of the privilege level of a bad actor. What makes E2EE so powerful is that data is being encrypted for only the individuals that may access that data - not even the server itself can read or act on the data.
Usually, end-to-end encryption is harder to implement as it can be complex; with REI3, its integrated into the platform and can be used by any REI3 application with little effort. However, some limitations exist as encrypted data is not accessible to REI3 on the backend (server side).
For more information on how end-to-end encryption is implemented in REI3, please take a look at the concept document.
Beware! Because E2EE blocks even the system itself from reading the data, only users that already have access to it may read or re-encrypt the data for others. Neither administrators, nor the REI3 developers can access encrypted data for which privileged users have lost access to.
How to use
Application authors can enable E2EE for a new relation within the Builder. With encryption enabled, new attributes of a relation can be set to be encrypted. After that, data will be automatically encrypted for the current user when saved on data forms and decrypted when accessed by things like lists.
For E2EE to work, users that work with encrypted data need to setup their personal encryption once inside the user settings interface. If they attempt to work with encrypted data without that setup, an error message will be shown.
When a user attempts to read encrypted data that was not encrypted for it, an error message is shown. It is up to the application author to filter records, based on things like record ownership or group membership, to make data accessible to only privileged users.
Encrypt for multiple users
By default, REI3 encrypts for the current user only. Sometimes sensitive data needs to be shared between individuals or groups however. For this, REI3 can receive a list of users to encrypt data for. This is done by calling a specific frontend-function when a list of privileged users is set or updated.
Example: A record is by default accessible to its creator and should be encrypted as such; this works automatically once the relation and specific attributes are set to be encrypted. The creator can however share access with others by selecting a list of contacts from its organization within a relationship input field. When this field is updated, the frontend function 'app.set_e2ee_by_user_ids(user_ids)' is called with an array of user IDs from the selected contacts. As not every contact is necessarily connected to a user (see user sync), the relationship input should be filtered to contacts with assigned users. With user IDs set by the frontend function, REI3 will automatically encrypt the data for all affected users. If any selected users do not have encryption enabled, an error message will be shown.
Encrypt for groups
A bit more work but also supported: Encrypt data for groups instead of specific individuals.
There are generally two scenarios:
- Assign a group to a record to have access to that record. In this case, a frontend function would call a backend function to resolve all user IDs from all members of this group. It would then use the result to call the function 'app.set_e2ee_by_user_ids(user_ids)' to encrypt data for all group members.
- Assign members to a group that already has access to specific records. In this case, we would update encryption for one or many records on a different relation. For this the frontend function 'app.set_e2ee_by_user_ids_and_relation(user_ids,relation_id,record_ids)' exists. You would still set the user IDs (all current group members + all other users that already have access), the relation ID (the relation of the encrypted record) and the record IDs (IDs of records that the group has access to).
The REI3 'Password Safe' application includes implementations of all of the above cases and can be used as a reference.
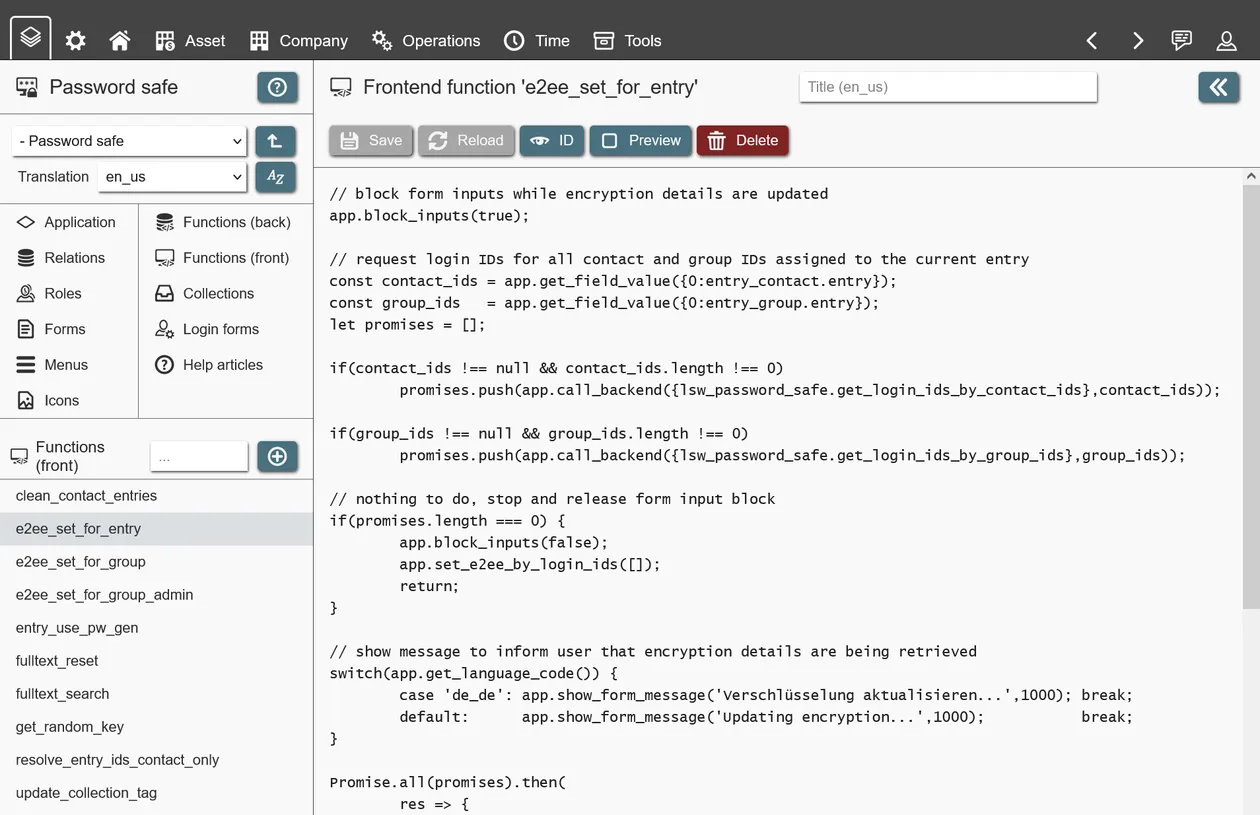
Limitations
Because E2EE only allows specific individuals to access encrypted data, the REI3 system itself cannot use it for things like filtering or sorting. Full-text search over encrypted data is possible with the use of both backend functions to retrieve and frontend functions to decrypt and then search through plain data. It is however necessary that the user executing those functions is privileged to access that data; without it being encrypted for this particular user, the data cannot be decrypted and therefore not processed.
Additionally, E2EE in REI3 requires additional overhead in the form of computation time for the en-/decryption itself, as well as space to store individual user´s decryption keys.
Because of the given limitations, E2EE should only be enabled where necessary - enabling it for everything will result in worse system performance and user experience.
Building on applications
A major feature of REI3 is the ability to build on other applications. To access data, user interfaces, roles and more to extend functionality or to better meet niche requirements. Building on applications enables anyone to re-use parts of applications while adding their own, unique features. No license or permission is required to extend an existing application. Multiple applications can build on the same, original application, using the same or different sets of components.
If you want to extend another application, you create a new application that has access to the application you want to extend. This is done in the Builder start page by selecting a dependency with 'Depends on' when creating/updating an application. This enables access to different parts of the original, dependent upon application - to keep things simple, we will call this the 'parent application' from here on.
Extending applications means that every new version of your application requires the parent application to be installed as well. When exporting your application, dependencies (parent applications) will be included automatically.
NEVER make changes to parent applications directly. The Builder will not prevent this, but all changes will be removed when an update to the parent application is installed. To build on other applications, you make changes to your own application that can show and reference parts of its parent application(s).
Once your application has a parent, you can access the following components:
- Data (relations & attributes): Access to parent relations in relationships within the child application; effectively extending these directly (with 1:1 relationships) or creating new data structures attached to the parent relations. Parent relations & attributes can also be accessed in queries, enabling access to these as if they were part of the child application.
- Forms: Access to forms from the parent application as targets in data display fields, buttons or within menus. This allows for re-use of existing user interfaces.
- Menus: Access to menus from the parent application. It is also possible to copy an entire menu structure of an application to quickly recreate the parent, while making desired changes to specific menu entries.
- Functions: Parent functions (backend & frontend) can be accessed directly, while access to entities from within functions in the child application is also enabled. To keep applications upgrade safe, always use the provided placeholders when referencing entities in functions. This will not protect against deletions (see below) but will keep your application running when entities are renamed.
Extension scenarios
Depending on the specific case, different approaches to application extension are possible.
Accessing shared components
Extending applications can be useful, when working on very different applications that still need to access already existing features. An often used example is the application 'Organizations'. It offers organizational structures that many applications need but do not want to re-implement. By choosing 'Organizations' as parent application ('Depends on'), its components are available for, for example, using existing departments and employee data inside the child application. This can be used to build relationships with employees ('Assets being assigned to' or 'Workflows executed by') and avoids data duplication.
Implementing small changes
Another, common use case is the 'overwriting' of existing applications. When an application does 90% of what is needed, but requires alteration or extension. By extending the parent application, the original menus and forms can be accessed for the parts of the application that fit with the existing requirements. Missing features or desired changes to user interfaces can then be implemented by creating new relationships & forms in the child application and changing the menu references accordingly. At last, the parent application can be hidden with the admin UI or its roles not be assigned to only give access to the 'overwriting' application.
Important considerations
User access
Accessing parent components is simple within the Builder. Users, however, still require privileges. A good practice is for applications to define separate 'data only' roles (just data access, no menus) that can be inherited by child application roles to give users access to data without immediately showing all the parent´s UIs. When designing your own applications, you should always consider setting up 'data only' roles so that applications building on yours will be able to easily integrate.
When 'data only' roles are not available, parent roles can still be inherited, while the parent application would then need to be hidden with the admin UI. This is not ideal in some use-cases but allows for dependencies with applications that do not follow good practices.
Deletions
Another important consideration is that application authors can decide to delete entities. Dealing with renamed or changed entities in applications is handled by REI3 automatically (except in functions when placeholders are NOT used); it´s a different story when referenced entities in parent applications are deleted. Deleting an entity is blocked by the Builder if a referring child application is installed in the same instance. Unfortunately, other application authors might not know about your application and/or might not have it installed in their instances, so REI3 cannot always prevent this situation.
When an updated parent application is attempting to install itself in a REI3 instance that still refers to a now deleted entity, REI3 will block this installation. This protects the currently running system from breaking but will cut off future updates for the parent application. As this is usually not a desirable state, application authors need to address this situation. The process usually goes as follows:
- Identification of the change reason. Why was this entity deleted? Was it moved to another application? Is the parent´s application author not interested in keeping it? etc. To learn this, the author can be contacted or the newer application version installed in a different REI3 instance to check the changes directly.
- Once it is clear, why the change occurred, the situation can be addressed. If only UIs were deleted, these can easily be recreated or different ones referenced with a newer application version. When data is affected that needs to be kept, a new application version (still referencing the older, valid parent) can offer CSV exports for the 'old' data. Then the child application is updated to remove the old reference, update to the new parent version and offer an CSV import for the old data to be re-imported. Depending on the reason for the removal from the parent application, either new data entities will be referenced (if they were moved) or data entities might need to be re-implemented inside the child application (if they were removed).
Because the process of fixing references, especially for data (relations/attributes), can be a lot of effort, always consider keeping outdated data entities, at least for a couple of releases. Even if they are going to be removed eventually, keeping them in the system allows dependent authors to more easily migrate data to the new data structure. A good practice is to rename relations / attributes that are to be removed and only removing them after a year or two; this gives dependent application authors time to react to these changes.
Application transfers
An application transfer is the process of exporting a signed and compressed version of an application from one REI3 instance and importing it into another. Any installed application can be exported from any REI3 instance with the Builder. It does not matter if the application was originally built inside the running REI3 instance or was imported. It is also irrelevant who the original author was. There is no encryption or obfuscation added at any point.
To protect against unknown sources, REI3 instances employ a list of trusted public keys. The public key of the central REI3 repository is included in all instances by default. To export applications, you need to provide your own private key for signing them. The Builder includes tools to create new RSA key pairs for convenience. The private key should be considered highly sensitive. If you are not familiar with handling secure key pairs, please refer to external resources to learn more.
Exporting applications
Applications are exported on the Builder start page. To start the export process you select the desired application and run an export check. This check will compare the current state of the application to the last known version. If any changes exist, a new version must be created before an export is possible. By creating a new version target instances understand that there are changes to apply. In order to export any changes, an application must be set to 'export changes' in the admin UI for applications. You should only do this for your own applications.
Important notice: When you build on applications from other authors, these are dependencies that are automatically exported together with your application. To protect against accidentally making changes to applications from others, all applications are in the state 'do not export changes' by default. While in this state, the last imported version of the application is exported and not the potentially changed version, accessible in the Builder. If you decide to export new versions for applications built by others, you potentially risk loss of your changes as well as data loss, when a new version from the original author is installed. You can safely build on other applications without making direct changes.
Ultimately, the export will generate a compressed zip file, which includes your application and all its dependencies. Within the zip file, each application is represented as a *.json file, which contains the corresponding application structure and a signature, created with your private key. Applications that were not changed are exported as they were with their original signature.
Importing applications
Applications can be imported to REI3 instances in two ways:
- By importing an application package file.
- By importing an application from a repository.
When you attempt to import your application into another REI3 instance, the signature of the application is checked against a list of trusted public keys. Only applications which signature can be successfully compared to these trusted public keys can be imported. You can add your public key to any REI3 instance within the admin UI.
Applications are either installed or updated when they are imported. All changes made to the applications or their dependencies are automatically applied by REI3. Should there be a problem, the entire import process is reverted even if multiple applications were affected. Import issues can be checked inside the admin UI by increasing the log level for 'transfers' and repeating the import.
Hosting a repository
When running many local or offline REI3 instances, it can be sensible to host your own REI3 application repository. It is also possible to host your own repository in the cloud, accessible to anyone. This is done by setting up a REI3 instance and installing the 'REI3 repository' application; this is the same application we use to host the central REI3 repository.
Once running and reachable on a network, the repository must be added to target REI3 instances as well as the public signing key(s) for corresponding applications. After that the repository meta data will be pulled from connected instances and applications will be available for install/update.
Optimizing for mobile devices
All REI3 applications work on mobile devices without doing anything special. Graphical elements, like forms, menus, input fields and so on, are designed to look and work well with different screen sizes.
While it is true that all applications are usable on mobile devices, some adaptations should be considered to improve usability. It is for example possible to use the same large, full page lists on mobile as on a desktop - they will work the same and will look good enough. However, it is much easier to deal with list views on mobile devices, if they do not scroll in multiple directions. The same is true for complex forms. REI3 will size and scroll on smaller devices, but adapting forms will often result in a better user experience.
Multiple options exist to adapt applications for smaller screens:
- Data fields (relationship inputs, lists, calendars, Gantts, etc.) have a 'mobile device' toggle for each column. If toggled off, these columns are not shown if the screen size is too small. In most cases it is easier for mobile device users to see less data and click on a specific record to get details than to scroll a large view.
- Forms offer hiding of specific fields/containers for mobile devices. While it is not useful to hide important input fields, on some forms, related data is shown because there is more screen space available; these fields can be hidden on mobile devices to make form handling easier.
To simulate mobile devices, resizing the browser window is sufficient - REI3 will switch to mobile view when the screen space reaches a threshold. With small adjustments, existing forms/list views can be adjusted for better usability on mobile devices without sacrificing functionality. Even if applications are not meant to be used on these devices, it is always welcome when no other device is available and the application just works.
Working with emails
REI3 can retrieve emails from IMAP mailboxes and send emails with SMTP. Mail functions are executed by a central mail spooler, included in every REI3 instance. This spooler periodically fetches and sends emails with defined mail accounts.
To enable mailing features for different applications within the same instance, unique mail account names can be chosen by administrators. These account names can then be used in backend functions to process messages coming in from (or be send with) defined mail accounts. By adding corresponding options in their applications, authors can let administrators choose the appropriate mail account.
Sending an email
The instance function 'instance.mail_send()' can be called from any backend function from any application. Specific parameters include mail related meta data (like recipient, subject line and mail body) as well as optional parameters for attaching files from file attributes and for using a specific mail account to send with. Each time this function is called, a single email is created. More details can be found in the help text for this function in the Builder.
The mail spooler periodically dispatches emails - if no account is specified, a random account is used. HTML emails can also be sent; usually created from the value of a record´s text attribute, filled by a richtext field input on an email send form.
Receiving emails
If receiving mail accounts are specified, the mail spooler periodically fetches emails and their attachments. With the instance function 'instance.mail_get_next()', any application can request the next available email from the mail spooler, optionally filtered to a specific account. The idea is to call this function in a loop until all emails are processed; this function returns NULL when no more emails are available. Once an email is processed, it should immediately be deleted; if this is not done, it might be processed twice. Because of that 'instance.mail_get_next()' will return the same message again if it was not deleted. More details can be found in the help text for this function in the Builder.
To delete a processed email, two options exist:
- Delete it right away with 'instance.mail_delete()'. Used when no attachments are to be handled. Email is immediately deleted and attachments (if there) are lost.
- Order REI3 to copy the email attachments and then delete it with 'instance.mail_delete_after_attach()'. Used when a record exists (or was created) with an files attribute that should receive the email attachments. REI3 will then transfer these files and update the record´s files attribute value accordingly - after which the email is deleted. This process runs in the background and might take some time depending on schedulers and attachment size; 'instance.mail_get_next()' will skip emails marked as such and return the next, unmarked email from the spooler.
Date and time management
When dealing with date and/or time values, it is important to separate different types. Dates, as in the 3rd of August 2020, are usually meant to be the same everywhere - the day might start later in a different timezone but we are talking about the same entity (as in 'day of a year'). Public holidays and vacations are often set to dates and have no time component. Date+time values (we call them 'datetime' for short) however, as in 3rd August at 12:30, are usually understood to be relative. When making an appointment with someone across timezones, we expect a system to handle the date & time relative to us but still allow everyone to meet at the same point in time.
In computer systems there are multiple approaches to store, manage and display date & time values. They can be combined, timezone information applied to or kept separately from the value itself and so on.
REI3´s implementation works as follows:
- All date/time values are stored in the database as unix timestamps. A unix timestamp stores time as an offset in seconds to a fixed point in time (which is '1970-01-01 00:00:00 at UTC').
- To store date/time values, integer or bigint values are used. Unix timestamps require bigint when storing dates/datetimes bigger than '2038-01-19 03:14:08 UTC' as this is the maximum timestamp representable by a 32 bit signed integer.
- Values are presented in frontend elements, like field inputs or lists, depending on the chosen value type for an attribute ('date + time', 'date' or 'time').
- The different value types are handled as such:
- Dates: A 'date' represents a 'day in a year'. When entering a date, it is stored as midnight at UTC of the corresponding day. So choosing the 2nd August 2017 will be stored as unix timestamp '1501632000' or '2017-08-02 00:00:00 UTC'. Because all date values are stored as midnight, they can directly be compared. Timezone information is not stored or used at all in this context.
- Time: A 'time' represents a 'point of time on a clock'. When entering a time, it is stored as the offset to unix zero ('1970-01-01 00:00:00'). Because there is no date component, the highest possible value is the count of seconds until '23:59:59' (or 86399 as unix timestamp). This implementation allows comparison between time values. Similar to dates, timezones are not used in this context.
- Datetime: A 'datetime' represents a 'timezone adjusted date & time'. When entering a date & time, the local timezone is subtracted from the value and it is stored as the corresponding unix timestamp. When the same value is shown back to a user, its timezone will be added, showing the correct relative date & time. The relative date & time might be different, depending on timezone and daylight savings time - the point in time will be the same however. The timezone information that was used to enter the original value is not stored.
With this implementation, attributes storing dates must be handled separately to attributes storing datetimes or just times. As date/time values are not bound to timezones but datetimes are, displaying a date value as datetime will be wrong. Date, time & datetime values can directly be compared with values of the same type but not between each other. The only exception is the option of mixing dates & datetimes in date range inputs (combined from/to input) and calendars. This is useful when dealing with events and appointments in a mixed context. Without a date range, the right context (whether we have a date or datetime) cannot be safely assumed.
User sync
It is often necessary, to connect data in REI3 to users working in the system. This often takes the form of a 'user relation' that contains additional, application specific data and/or can be referenced in relationships. Some examples:
- The application wants to store things like 'created by' or 'changed by' for all or particular relations. In this case, the corresponding relations would contain relationship attributes pointing to the 'user relation'.
- The application wants to control access to records, based on a group membership system. Both 'groups' and 'users' are relations in the application, which are in a relationship to each other (eg. 'users' can be members of 'groups'). This relationship can then be used to filter data in the frontend or, even better, in relation policies.
To enable these sorts of use cases, records on a 'user relation' need to be connected to users working in the system so that filtering can happen live. This is done by having an attribute on the 'user relation', which contains the ID of the connected user. This attribute value can then be used everywhere in REI3, to be compared against the current user ID in things like filters or form state conditions.
To get the user ID in the first place and to automatically create and update records in the 'user relation' of the application, REI3 offers a so called user sync function. This is a backend function, which can be created and then selected in the 'Application' page in the Builder.
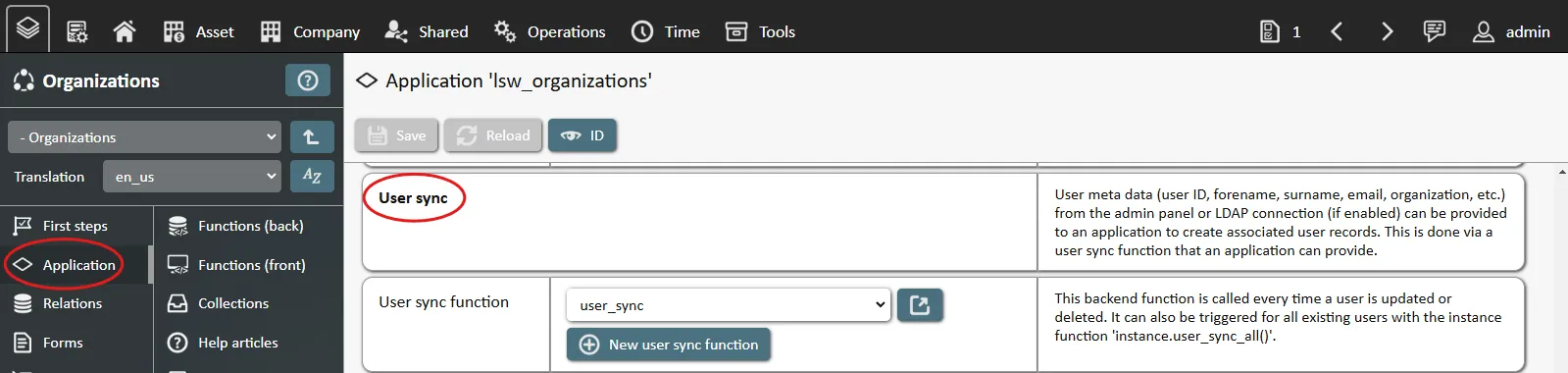
The chosen user sync function is called by REI3 whenever a user is updated or deleted - regardless if that happens manually in the admin panel or automatically during a user import from LDAP. The user sync function contains both the event (user was 'UPDATED' or 'DELETED') as well as user meta data (user ID, username, is_admin, is_active, email, department, mobile phone, etc.).
When creating the sync function from the 'Application' page in the Builder, or when selecting the 'User sync function' template in the 'New backend function' UI, it contains a full example on how synced user data can be applied to relations in an application. The specific implementation is however up to the author, as applications can work very differently. The only important part is that the user ID is ultimately stored in the 'user relation' and does not exist twice; a unique index can help to ensure this.
CSV import and export
Importing and exporting large data sets with CSV is done by enabling CSV options on any list field. After CSV options are enabled, CSV actions are available on the list field UI. There some things to consider when working with CSV:
- File attributes cannot be handled with CSV - they can neither be imported nor exported.
- Column batches should not be used. Example: A common column batch 'forename + surname of a person' is great for presentation but attributes (forename/surname in this case) need to be specifically addressable for CSV updates to be safe.
- For CSV imports, the relation join options (see Queries) define how records are handled. If (C)reate is enabled, new records are being created when they cannot be looked up, while (U)pdate allows updating of existing records. With multiple, joined relations, a single CSV line can create/update multiple records.
- To look up records during CSV imports, unique indexes are used. These can be selected as criteria in the query for the CSV list field. Unique indexes are created on the corresponding relation. If in the query dialog no unique index is available, the corresponding relation lacks one; in this case records can only be created, not updated. Make sure that all attributes used for the selected unique indexes are actually columns in the CSV list; otherwise required unique index components are missing and the index cannot be used.
- Sub queries are not compatible with either CSV import nor export.
Troubleshooting
Application fails to import in target instance
Many potential import issues are considered and automatically handled by REI3. If the import still fails however, you can increase the log level for transfers and repeat the import attempt; this will generate usable logs. To troubleshoot, here are some pointers:
- The import process is handled sequentially. First relations then attributes and so on. In some cases, entities can cross-reference (like form fields referencing other fields or presets referencing other presets). In these cases, the import process will skip the problematic entity and finish others first. It will then repeat the import process, skipping already imported entities. Import tasks rely on deferring constraints to allow for cyclical references. It will ultimately fail, if any issues still exist at the end of at most 10 loops.
- Some imports fail, because the application was released for an older version of REI3. Older applications can generally be imported without issues - but in some cases, very old applications might have trouble with current releases. In this case, you can import the application in an older version of REI3 and then upgrade the instance to your target version. During platform updates, applications are automatically updated as well. If you are the author of the application in question, you can then export your application from the newer release to avoid import issues for others. If you are not the author, please contact the author and ask for an updated version for your release.
- Some issues are not solvable because changes are just invalid in target instances. Examples:
- Adding a not-nullable attribute to an existing relation without default value. If your application is imported to an instance where an older version of your application already existed, the import can fail because adding such an attribute is invalid for existing records. The attribute must either be nullable or provide a default value to update existing records.
Application causes SQL errors
The Builder guides an application author to create valid data retrieval/manipulation logic so SQL errors usually do not happen. Due to the available range of options, some logic errors cannot completely be avoided however. Examples:
- Using 'GROUP BY' on some list columns, while others are not grouped or aggregated. This is generally nonsensical - if this issue occurs you must change these settings. You can also use the SQL preview in the form-builder UI to check/test the resulting SQL against your database.
- Using invalid operators, like comparing strings with 'larger than'.
- Having logic errors in functions. Besides offering placeholders for upgrade safe access to existing entities, the Builder will deliver an error if the function has invalid syntax. Logic errors however will not be caught. Please test your functions thoroughly.
Data display fields not showing expected records
When designing complex data display fields with many joins, sub queries, groupings, filters and so on, logic errors or badly chosen configuration options can result in non-desirable data sets. To troubleshoot this, a SQL-preview function is available on the data display field when inside the Builder. This returns the raw SQL that is being used to retrieve the current list data. With this preview, you can directly see how the chosen options affect the final SQL query.